고정 헤더 영역
상세 컨텐츠
본문
I. 분산분석(ANOVA)
1. 개요
(1) 세 개 이상의 모집단이 있을 경우에 여러 집단 사이의 평균을 비교하는 검정방법
(2) 세 집단 이상의 평균비교에서는 독립인 두 집단의 평균 비교를 반복하여 실시할 경우에 제1종 오류가 증가하게 되어 문제가 발생한다.
(3) 이를 해결하기 위해 Fisher가 개발한 분산분석(ANOVA, ANalysis Of Variance)을 이용하게 된다.
(4) 분산분석의 귀무가설은 항상 ‘집단간의 평균의 차이는 같다’이다.
(5) 단점: 귀무가설을 기각할 경우 어느 집단 간의 평균이 같은지, 혹은 어느 집단간의 평균이 얼마나 다른지 알 수 없다.
(6) 그래서 분산분석의 귀무가설을 기각했을 경우 어느 집단 간에 차이를 보이는지 알기 위해 사후 검정 시행
(7) 독립변수: 범주형, 종속변수: 연속형
(8) F-value 사용
$$F-value = \frac{집단간 분산}{집단내 분산} $$
(9) 집단간의 평균의 분산이 클수록 각 집단의 평균은 서로 멀리 있기 때문에 분산의 개념을 사용
☞ 집단간 차이비교 용이
(10) 가정
1) 관측치 독립성 - 상관관계를 통해 확인
2) 정규분포를 따르는 집단 – 정규성확인
3) 각 정규분포의 표준편차가 모두 동일(등분산성) – 등분산성 확인
2. 일원분산분석(one-way Anova)
(1) 셋 이상의 집단 간 평균을 비교하는 상황에서 하나의 집단에 속하는 독립변수와 종속변수 모두 한 개일 때 사용
ex)
|
종속변수(tv시청시간) |
|
|
청소년 |
일평균1시간 |
|
성인 |
일평균30분 |
|
노인 |
일평균10분 |
(2) 검정
1) 등분산성 성립
① anova_lm()사용
i. 모듈
a. from statsmodels.formula.api import ols
b. from statsmodels.stats.anova import anova_lm
ii. 모델생성: model = ols('종속변수컬럼~C(독립변수컬럼)', DataFrame).fit()
a. DataFrame형의 데이터를 사용
b. 범주형 데이터를 사용하는 독립변수 앞에는 C를 붙여줘야 한다.
iii. anova_lm(model): 분산 분석표 반환
# 검정방법1
df = pd.DataFrame(data, columns=['value', 'group'])
print(df)
model = ols('value~C(group)', df).fit() # C(변수명+...): 범주형임을 표시 해줘야 함
print(anova_lm(model, typ=1))
※ 분산분석표
|
요인 |
자유도(df) |
제곱합(sum_sq) |
제곱평균(mean_sq) |
F 비 |
p-value (PR(>F) |
|
처리 (독립변수) |
a = 집단 수 - 1 |
 |
MSR = SSR/a |
F = MSR/MSE |
종속변수의 p-value |
|
잔차 (Residual) |
b = 전체데이터 – 집단 수 |
 |
MSE = SSE/b |
- |
|
|
계 |
a + b = 전체데이터 - 1 |
 |
- |
- |
- |
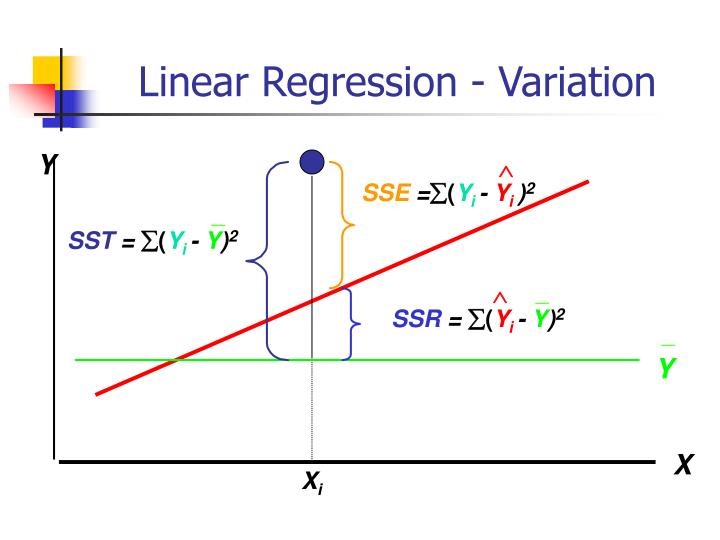
n SSSE(residual sum of squares): 잔차들이 자신의 표본평균으로부터 벗어난 편차의 제곱
n SSR(explained sum of squares): 표본평균과 종속변수 값 중 독립변수에 의해 설명된 부분과의 차이를 제곱하여 합한 것
n SST(total sum of squares): 종속변수의 관측 값과 표본의 평균의 차이(편차)를 제곱하여 합한 값
SST = SSR + SSE
② stats.f_oneway(집단1, 집단2, 집단3) 사용: f-value와 p-value 반환
# 검정방법2
f_statistic, p_val = stats.f_oneway(gr1,gr2,gr3)
print(stats.f_oneway(gr1,gr2,gr3))
print('f_statistic: ', f_statistic)
print('p-value: ', p_val)
2) 등분산성 미성립
① from pingouin import welch_anova 모듈사용
② welch_anova(data=data, dv=’종속변수’, between='독립변수')
# 등분산성을 만족하지 못할 때 사용
from pingouin import welch_anova
print(welch_anova(data=data, dv='AMT', between='ta_gubun'))
# p-unc(p-value) 7.907874e-35 < 0.05 귀무가설 기각
3) 사후 검정: 그룹 간의 평균 차이가 의미가 있는지 확인
① from statsmodels.stats.multicomp import pairwise_tukeyhsd 모듈 사용
② pairwise_tukeyhsd(DataFrame.컬럼명(종속변수), DataFrame.컬럼명(독립변수), alpha = 유의수준)
i. TukeyHSDResults타입
ii. reject=True: 유의미한 차이가 있다
# 사후검정: 그룹간의 평균 차이가 의미가 있는지 확인
from statsmodels.stats.multicomp import pairwise_tukeyhsd
posthoc = pairwise_tukeyhsd(spp['AMT'], spp['ta_gubun'])
print(posthoc)
③ TukeyHSDResults.plot_simultaneous( comparison_name = None , ax = None , figsize = (10, 6) , xlabel = None , ylabel = None ): 각 그룹 평균의 범용 신뢰 구간 플로팅
# 사후검정: 그룹간의 평균 차이가 의미가 있는지 확인
from statsmodels.stats.multicomp import pairwise_tukeyhsd
posthoc = pairwise_tukeyhsd(spp['AMT'], spp['ta_gubun'])
print(posthoc)
# reject=True: 유의미한 차이가 있다
posthoc.plot_simultaneous()
plt.show()
3. 이원분산분석(two-way Anova)
(1) 일원분산분석 수행 시 독립변수의 수가 두 개 이상일 때 사용
(2) 독립변수 간 교호작용이 있다고 판단될 때는 ‘반복 있는 실험’
(3) 교호작용이 없다고 판단될 때는 ‘반복이 없는 실험’
(4) 교호작용: 독립변수끼리 서로 영향을 미치는 경우 = 상호작용
ex)
|
독립변수(연령별) |
종속변수(tv시청시간) |
|
|
청소년 |
남성 |
일평균 1시간 |
|
여성 |
일평균 1시간30분 |
|
|
성인 |
남성 |
일평균 30분 |
|
여성 |
일평균 50분 |
|
|
노인 |
남성 |
일평균 10분 |
|
여성 |
일평균 5분 |
|
(5) 함수
1) 모듈
① from statsmodels.formula.api import ols
② from statsmodels.stats.anova import anova_lm
2) 교호작용 없을 때
i. 모델생성: model = ols('종속변수컬럼~C(독립변수컬럼1) + C(독립변수컬럼2)', DataFrame).fit()
ii. anova_lm(model): 분산 분석표 반환
(p, q: 집단의 수)
|
요인 |
제곱합(sum_sq) |
자유도(df) |
제곱평균(mean_sq) |
F비 |
p-value (PR(>F) |
|
독립변수컬럼1 |
SSA |
p - 1 |
MSA = SSA/p-1 |
MSA/MSE |
p-value |
|
독립변수컬럼2 |
SSB |
q - 1 |
MSB = SSB/q-1 |
MSB/MSE |
p-value |
|
오차(Residual) |
SSE |
(p-1)(q-1) |
MSE=SSE/(p-1)(q-1) |
|
|
|
계 |
SST |
pq - 1 |
|
|
|
3) 교호작용 있을 때
i. 모델생성: model = ols('종속변수컬럼~C(독립변수컬럼1) + C(독립변수컬럼2) + C(독립변수컬럼1):C(독립변수컬럼2)', DataFrame).fit()
ii. anova_lm(model): 분산 분석표 반환
(p, q: 집단의 수, r: 반복횟수)
|
요인 |
제곱합(sum_sq) |
자유도(df) |
제곱평균(mean_sq) |
F비 |
p-value (PR(>F) |
|
독립변수컬럼1 |
SSA |
p - 1 |
MSA = SSA/p-1 |
MSA/MSE |
p-value |
|
독립변수컬럼2 |
SSB |
q - 1 |
MSB = SSB/q-1 |
MSB/MSE |
p-value |
|
C(독립변수컬럼1) : C(독립변수컬럼2) |
SSAB |
(p-1)(q-1) |
MSAB=SSAB/(p-1)(q-1) |
MSAB/MSE |
p-value |
|
오차(Residual) |
SSE |
pq(r-1) |
MSE=SSE/ pq(r-1) |
|
|
|
계 |
SST |
pqr - 1 |
|
|
|
# 태아수와 관측자수의 상호작용 없음
reg = ols('data["머리둘레"] ~ C(data["태아수"]) + C(data["관측자수"])', data = data).fit()
result = anova_lm(reg, type=2)
print(result)
# 태아수와 관측자 수 의 상호작용
formula = '머리둘레 ~ C(태아수) + C(관측자수) + C(태아수):C(관측자수)'
reg2 = ols(formula, data).fit()
result2 = anova_lm(reg2, type=2)
print(result2)
'데이터분석 by파이썬' 카테고리의 다른 글
| 회귀분석 - 1. 개요 (0) | 2021.03.22 |
|---|---|
| 상관분석 (0) | 2021.03.12 |
| t – test (0) | 2021.03.09 |
| 교차분석(카이제곱분석) (0) | 2021.03.07 |
| 통계분석 - 추정과 가설검정 (0) | 2021.03.07 |




