고정 헤더 영역
상세 컨텐츠
본문
1. 모델 無: from sklearn.datasets import make_regression
(1) make_regression( n_samples = 100 , n_features = 100, bias = 0.0 , coef = False/True)
(2) 0이 아닌 회귀 변수가 있는 (잠재적으로 편향된) 임의 선형 회귀 모델을 적용하여 생성
(3) n_samples
1) 기본값 = 100
2) 샘플 수
(4) n_features
1) 기본값 = 100
2) 독립변수 개수
(5) bias = 0.0: y 절편
(6) coef = True
1) 기울기
2) 디폴트 값 False
(7) 반환값
1) X ndarray of shape (n_samples, n_features)
① 입력 샘플
② 2차원 matrix로 반환
2) y ndarray of shape (n_samples,) 또는 (n_samples, n_targets): 출력 값.
3) coef ndarray of shape (n_features,) 또는 (n_features, n_targets)
① 기본 선형 모델의 계수(기울기)
② coef가 True 인 경우에만 반환
from sklearn.datasets import make_regression
import numpy as np
np.random.seed(12)
# 모델생성
print('방법1: make_regression사용. model 없다.(연습용)--------------------')
# 방법1: make_regression사용. model 없다.
x, y, coef = make_regression(n_samples=50, n_features = 1, bias=100, coef=True)
# n_features = 1: 독립변수의 수, 기울기: coef, 절편: bias
print(x) # 독립변수는 2차원 matrix
print(y)
print(coef) # 기울기: 89.47430739278907
# 회귀식: y = 100 + 89.47430739278907 * x
y_pred = 100 + 89.47430739278907 * (-0.67794537)
print(y_pred)
print()
# 새로운 값 확인
y_pred = 100 + 89.47430739278907 * 66
print(y_pred) # = 6005.304287924078
2. 모델 有
(1) from sklearn.linear_model import LinearRegression
1) 모델 = LinearRegression().fit(X, y)
2) 일반 최소 제곱 선형 회귀.
3) 계수 w = (w1,…, wp)를 사용하여 선형 모델을 fit()하여 데이터 세트에서 관찰 된 대상과 선형 근사에 의해 예측 된 대상 간의 잔차 제곱합을 최소화
4) X: 2차원 배열의 학습시킬 데이터(독립변수) ex) 문제지
5) y: 차원에 상관없는 출력 값 ex) 해답
6) 속성
① 모델.coef_: 기울기, 종속변수와 같은 차원으로 반환
② 모델.intercept_: y절편
7) 예측: 모델.predict(X)
(2) X: 2차원 matrix형태의 매개변수
① 학습한 모델로 매개변수 X의 값을 예측
2) summary()사용 불가
3) 모델.score( X , y , sample_weight = 없음 ): 결정 계수 반환
# model 사용
print('방법2: LinearRegression사용--------------------')
# 방법2: LinearRegression사용.
from sklearn.linear_model import LinearRegression
# sklearn은 학습시킬 때 fit()메소드를 사용
xx = x
yy = y
model = LinearRegression()
fit_model = model.fit(xx, yy) # 학습데이터로 모형 추정: 절편과 기울기 획득
print(fit_model)
print('기울기:', fit_model.coef_) # 기울기
print('절편:', fit_model.intercept_) # 절편
# 예측값 확인 함수
y_new = fit_model.predict(xx[[0]])
print('predict로 새로운 값 확인:', y_new)
print('실제 답:', yy[0])
# 새로운 값 확인
y_new = fit_model.predict([[66]])
print('predict로 새로운 값 확인:', y_new)
print()
y_pred = 100 + 89.47430739278907 * 66
print(y_pred) # = 6005.304287924078
(3) import statsmodels.formula.api as smf
1) 모델 = smf.ols(formula, data, drop_cols=None)
2) formula
① ‘종속변수~ 독립변수1 + 독립변수2+..’
② 모델을 지정하는 공식
③ data가 DataFrame형인 경우 컬럼명으로 변수를 지정
④ 독립변수가 많을 때는
'종속변수 ~ ' + "+".join(data.columns.difference([제외할 컬럼명들]))

3) data = 모델에 대한 데이터(DataFrame)
4) drop_cols: 모델생성에서 제외할 컬럼 지정
5) 모델.summary(): 모델의 통계정보들 표로 반환

6) 예측: 모델.predict(X)
① X: DataFrame을 대상으로 모델을 생성했기 때문에 매개변수의 형태도 DataFrame의 형태
② X = pd.DataFrame({독립변수 컬럼명1:[값들], 독립변수 컬럼명2:[값들]….})
③ 학습한 모델로 매개변수 X의 값을 예측
7) y절편과 기울기 확인
① intercept, slope = 모델.params
② slope, intercept = np.polyfit(독립변수, 종속변수, deg=1)
8) 결정계수 확인: 모델.rsquared
9) 변수와 y절편의 t-통계량의 p-value확인: 모델.pvalues
10) 신뢰구간 값: 모델.conf_int(alpha=0.05)

※ import statsmodels.api가 제공하는 dataset 불러오기
statsmodels.api.datasets.get_rdataset(‘dataset명’).data
import pandas as pd
import statsmodels.api
import statsmodels.formula.api as smf
import numpy as np
import matplotlib.pyplot as plt
# mpg: 연비(종속변수), hp: 마력(독립변수) => 마력이 커지면 연비는 작아짐(반비례)
mtcars = statsmodels.api.datasets.get_rdataset('mtcars').data
print('mtcars 데이터')
print(mtcars)

print('mtcars의 columns')
print(mtcars.columns)
print()
print('mtcars 요약통계량')
print(mtcars.describe()) 
print('mtcars 변수들의 상관관계')
print(mtcars.corr())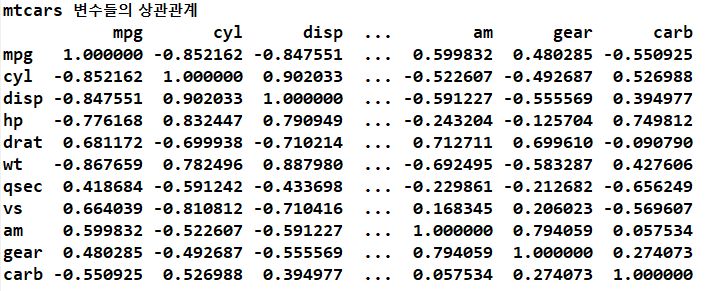
print('단순선형회귀-------------------------------------------------------')
result = smf.ols(formula='mpg ~ hp', data=mtcars).fit()
print(result.summary())
print()
print('summary 0번째 테이블')
print(result.summary().tables[0])
print()
print('summary 1번째 테이블')
print(result.summary().tables[1])
print()
print('summary 2번째 테이블')
print(result.summary().tables[2])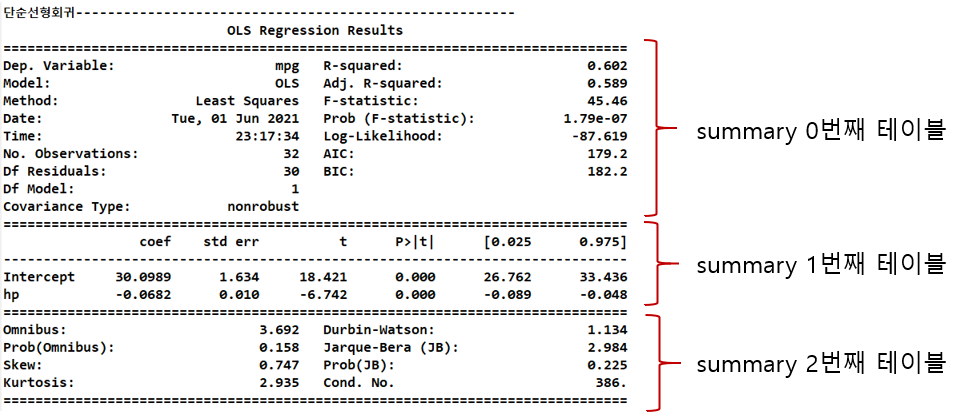
print('신뢰구간 값\n', result.conf_int(alpha=0.05))
print()
print('마력수 110에 대한 연비 예측:', slope*110 + intercept)
print(result.predict({'hp':110}))
# 마력이 증가하면 연비는 감소한다. 음의 상관관계이므로 결과는 반비례이다. 주의) 도구에 의한 결과는 맹신 불가, 참고자료로 사용
pred = result.predict()
print('hp = 110인 실제값:', mtcars.mpg[0])
print('hp = 110인 예측값:', pred[0])
print('다중선형회귀-------------------------------------------------------')
result2 = smf.ols(formula='mpg ~ hp + wt', data=mtcars).fit()
print('신뢰구간 값\n', result2.conf_int(alpha=0.05))
print()
print('마력수 110, 무게 5톤에 대한 연비 예측:', (-0.0318)*110 + (-3.8778)*5 + 37.2273)
print(result2.predict({'hp':110, 'wt':5}))
print()
# 14.3403는 믿을만한 예측값 ∵ R-squared도 높고, 변수간 관계도 유의미(p-value < 0.05)
(4) from scipy import stats
1) 모델 = stats.linregress(x, y)
2) slope, intercept, rvalue, pvalue, stderr 반환
3) 일부만 추출가능: 모델.slope/intercept/rvalue/pvalue/stderr
4) predict()지원 안함. 대신 numpy의 polyval([slope, intercept], data)로 예측 값 출력
import numpy as np
import pandas as pd
from scipy import stats
score_iq = pd.read_csv('../testdata/score_iq.csv')
x = score_iq.iq
y = score_iq.score
model = stats.linregress(x, y)
print('모델 정보\n', model) # stderr: 표준에러(잔차)
print()
# pvalue=2.8476895206683644e-50 < 0.05이므로 귀무가설 기각. 아이큐는 점수에 영향을 준다(대립가설 채택)
# => 현재 모델은 유의하다, p-value > 0.05이면 독립변수와 종속변수의 인과관계가 우연히 발생한 것 뿐
print('p-value:', model.pvalue)
print('기울기:', model.slope)
print('y절편:',model.intercept)
print('상관계수 r:', model.rvalue)
print('표준에러:', model.stderr)
# 기존의 값으로 확인
print('iq가 140일 때 예측결과:', model.slope * 140 + model.intercept) # 실제는 90
print('iq가 125일 때 예측결과:', model.slope * 125 + model.intercept) # 실제는 75
# 새로운 값으로 예측
print('iq가 80일 때 예측결과:', model.slope * 80 + model.intercept)
print('iq가 155일 때 예측결과:', model.slope * 155 + model.intercept)
# linregress는 predict()는 지원안함. numpy의 polyval 지원
# np.polyval: 다항식 계산 ex) np.polyval([3,0,1], 5) = 3 * 5**2 + 0 * 5**1 + 1
newdf = pd.DataFrame({'iq':[140, 125, 80, 155]})
print('예측결과\n', np.polyval([model.slope, model.intercept], newdf))
print()
print('전체 예측결과\n',np.polyval([model.slope, model.intercept], np.array(score_iq['iq']))) 
'데이터분석 by파이썬' 카테고리의 다른 글
| 분류(Classification) 평가지표 (0) | 2021.06.16 |
|---|---|
| 회귀(regression) 평가 (0) | 2021.06.06 |
| 회귀분석 - 4. 회귀분석 결과 해석 (0) | 2021.06.01 |
| 회귀분석 - 3. 유의성 검증, 결정계수 (0) | 2021.06.01 |
| 회귀분석 - 2. 선형회귀분석 (0) | 2021.06.01 |




