고정 헤더 영역
상세 컨텐츠
본문
1. 자연어: 사람들이 일상생활에서 자연스럽게 사용하는 언어
2. 자연어처리: 컴퓨터 공학적으로는 자연어를 입, 출력으로 사용하는 컴퓨터(프로그램)에 사용되는 처리과정
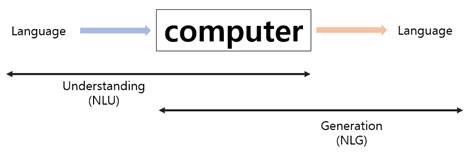
(1) NLU(Natural Language Understanding)
1) 자연어를 입력으로 받아들인 경우 자연어 이해라고 한다
2) 문자로 된 언어를 입력으로 직접 받아들여서 목적에 맞게 내부적으로 처리해내는 과정
ex) “카메라 실행해” -> 실제 카메라 실행
(2) NLG(Natural Language Generation)
1) 자연어를 출력하는 경우 자연어 생성이라고 한다.
2) 주어진 수치 등의 정보를 바탕으로 문자를 생성하여 사용자에게 자연어로 돌려줌
ex) 날씨앱: 온도를 숫자로 보여주면 ‘서늘한~’ 이라고 반환
3. 코퍼스(corpus-말뭉치)
(1) 통계 혹은 딥러닝 기반의 자연어처리에서 사용되는 매우 많은 수의 문장의 모음
(2) 크롤링이나 외부 문서들로부터 얻은 텍스트
4. 텍스트 전처리
(1) 용도에 맞게 텍스트를 사전에 처리하는 작업
(2) 토큰화(tokenization): 문자열은 토큰으로 나누는 작업
1) 토큰(token): 긴 문자열을 분석을 위해 의미 있는 작은 단위로 자른 것
2) 영어는 대부분 띄어쓰기를 기준으로 토큰화를 진행하면 단어 토큰화 가능
3) 한국어는 교착어라서 띄어쓰기 기준으로 토큰화를 하면 다양한 조사들이 붙어 같은 단어라도 다른 단어로 인식이 되면 자연어 처리가 힘들고 번거로워지는 경우가 발생
4) 한국어는 단어 토큰화가 아니라 형태소 토큰화로 진행
5) 품사 태깅(part-of-speech tagging): 단어 토큰화 과정에서 각 단어가 어떤 품사로 쓰였는지를 구분
ex) ('저자', 'Noun'), ('의', 'Josa'), ('허락', 'Noun'), ('을', 'Josa')
6) nltk라이브러리로 영어분석
7) 한국어는 KoNLpy(코엔엘파이)로 형태소 분석, 품사태깅 등의 작업 진행 – 좀 느림
(3) 정제(cleaning)
(4) 정규화(normalization)
※ 희소 표현(Sparse Representation): 벡터 또는 행렬(matrix)의 값이 대부분이 0으로 표현되는 방법, 희소벡터
ex) 원-핫 인코딩
※ 밀집 표현(Dense Representation): 희소 벡터의 반대.
벡터의 차원을 단어 집합의 크기로 상정하지 않음
사용자가 설정한 값으로 모든 단어의 벡터 표현의 차원을 맞춤
0과 1만 가진 값이 아니라 실수 값으로 표현
ex) word2vec
(5) 단어 임베딩(word embedding)
1) 단어를 밀집 벡터(dense vector)의 형태로 표현하는 방법
2) 임베딩 벡터(embedding vector): 밀집 벡터
3) 자연어로 되어있는 문장을 컴퓨터가 받아들일 수 있도록 각 단어(형태소)를 숫자들의 배열인 벡터로 변환
4) 단어(형태소) 단위로 문장을 분해할 때 많이 사용
5) 높은 차원의 벡터로 바꾸면서 비슷한 단어들은 벡터간 거리가 가깝게 위치하고 비슷한 관계를 가진 단어쌍 간의 거리와 방향을 비슷하게 한다.
6) 벡터로 변환 순서
① 각 단어에 고유번호 부여
i. 서로 다른 단어들을 수집하여 단어집(또는 단어집합 vocabulary)만들기
ii. 단어에 정수 인덱스 부여, 정수 인코딩
06) 정수 인코딩(Integer Encoding) - 딥 러닝을 이용한 자연어 처리 입문 (wikidocs.net)
② 벡터화
i. 원-핫 인코딩
ii. 카운트 기반의 벡터화 방법: LSA, HAL 등
iii. 예측 기반으로 벡터화: NNLM, RNNLM, Word2Vec, FastText 등
|
원-핫 벡터 |
임베딩 벡터 |
|
|
차원 |
고차원(단어 집합의 크기) |
저차원 |
|
다른 표현 |
희소 벡터의 일종 |
밀집 벡터의 일종 |
|
표현 방법 |
수동 |
훈련 데이터로부터 학습함 |
|
값의 타입 |
1과 0 |
실수 |
5. 원-핫 인코딩
08) 원-핫 인코딩(One-Hot Encoding) - 딥 러닝을 이용한 자연어 처리 입문 (wikidocs.net)
(1) 순열을 벡터로 바꾸는 가장 단순한 방법
(2) 단어집과 동일한 크기의 벡터의 값을 각 단어의 순열에 해당하는 위치에만 1, 나머지는 0으로 채우는 방식
(3) 한계
1) 단어의 개수가 늘어날 수록, 벡터를 저장하기 위해 필요한 공간이 계속 늘어난다
☞ 저장 공간 측면에서는 매우 비효율적인 표현 방법
2) 단어의 유사도를 표현하지 못한다
ex) 늑대, 호랑이, 강아지, 고양이라는 4개의 단어에 대해서 원-핫 인코딩을 해서 각각, [1, 0, 0, 0], [0, 1, 0, 0], [0, 0, 1, 0], [0, 0, 0, 1]이라는 원-핫 벡터를 부여 받았을 때, 원-핫 벡터로는 강아지와 늑대가 유사하고, 호랑이와 고양이가 유사하다는 것을 표현불가
☞ 사전 학습된 단어 임베딩 기술인 word2vec, ELMo, BEAT, ALBERT 등은 벡터공간에서 임베딩된 단어간의 상관관계를 보여준다. - 원-핫 인코딩의 한계를 보완
※ one-hot encoding은 단어의 의미를 전혀 고려하지 않으며 벡터의 길이가 총 단어 수가 되므로 매우 희박(sparse)한 형태가 된다는 문제가 있다. 이를 해결하기 위해 단어의 의미를 고려하여 좀 더 조밀한 차원에 단어를 벡터로 표현하는 것을 단어 임베딩(word embedding)이라고 한다.
# word를 수치화해서 vector에 담기
import numpy as np
# 단어 one_hot인코딩
data_list = ['python', 'lan', 'program', 'computer', 'say']
values = []
# 단어에 정수 인덱스 부여
for x in range(len(data_list)):
values.append(x)
print(values)
values_len = len(data_list)
# one_hot인코딩된 데이터 - 희소행렬
one_hot = np.eye(values_len)
# python은 0번째 니깐 0번째에만 1로 표시, lan은 1번째니깐 1번에만 1이 들어감(불빛들어간다고 비유)
# 문자들을 0과 1로 숫자표시, 가중치가 있는 곳에만 1로 표시
print(one_hot)
6. word2vec
(1) 단어 간 유사도를 반영할 수 있도록 단어의 의미를 벡터화 할 수 있는 방법
(2) 분산 표현(distributed representation) 방법
1) 기본적으로 '비슷한 위치에서 등장하는 단어들은 비슷한 의미를 가진다'라는 분포 가설(distributional hypothesis)이라는 가정 하에 만들어진 표현 방법
2) 분산 표현은 분포 가설을 이용하여 단어들의 셋을 학습하고, 벡터에 단어의 의미를 여러 차원에 분산하여 표현
ex) 강아지란 단어는 귀엽다, 예쁘다, 애교 등의 단어가 주로 함께 등장하는데 분포 가설에 따라서 저런 내용을 가진 텍스트를 벡터화한다면 저 단어들은 의미적으로 가까운 단어가 됨.
3) 저차원에 단어의 의미를 여러 차원에다가 분산하여 표현
4) 단어 간 유사도를 계산가능
5) NNLM, RNNLM 등이 있으나 요즘에는 해당 방법들의 속도를 대폭 개선시킨 Word2Vec가 많이 쓰임
(3) 계산량을 엄청나게 줄여서 기존의 방법에 비해 몇 배 이상 빠른 학습을 가능케 하여 현재 가장 많은 이들이 사용하는 Word Embedding 모델
(4) 학습을 시키기 위한 네트워크 모델 = 학습 알고리즘

1) CBOW(Continuous Bag of Words): 주변에 있는 단어들을 가지고, 중간에 있는 단어들을 예측하는 방법
2) Skip-Gram: 중간에 있는 단어로 주변 단어들을 예측하는 방법
3) 윈도우(window)
① CBOW에서는 중심 단어를 예측하기 위해서 앞, 뒤로 분석할 단어의 개수
ex) window = 4: 중심단어 기준 앞, 뒤로 4개씩 총 8개의 단어 분석
② Skip-Gram에서는 중심단어를 기준으로 앞, 뒤로 예측하는 단어의 개수
ex) window = 4: 중심단어 기준 앞, 뒤로 4개씩 총 8개 단어 예측
(5) genism.models 모듈 사용
(6) 생성자 Word2Vec(sentences=None, corpus_file=None, vector_size=100, window=5, min_count=5, sg=0)
1) 모델 생성
2) sentences = iterable: 토큰화 된 목록, 말뭉치
※ iterable한 타입 - list, dict, set, str, bytes, tuple, range
3) corpus_file = str: LineSentence형식의 말뭉치 파일 경로
4) size = int: 단어 벡터의 차원
5) window = int: 문장 내에서 현재 단어와 예상 단어 사이의 최대 거리, 중심단어로부터 앞, 뒤 개수
6) min_count = int: vocabulary에서 단어의 총 빈도가 int보다 낮은 모든 단어를 무시(미만)
7) sg = 0/1: 학습 알고리즘
① sg = 0: CBOW
② sg = 1: Skip-Gram
8) 추가 매개변수는 models.word2vec – Word2vec embeddings — gensim (radimrehurek.com) 참조
from gensim.models import word2vec
# 자연어 처리하려면 반드시 필요한 모듈
sentence = [['python', 'lan', 'program', 'computer', 'say']]
model = word2vec.Word2Vec(sentences=sentence, min_count=1,size=50)
# 배열의 크기: size, min_count=1: 단어최소빈도수=1개짜리부터 참여
(7) 속성
1) model.wv[‘단어’]: 단어를 벡터화. 설정해 놓은 model의 size만큼 벡터 생성
2) model.wv.vocab: key-value형식 ‘단어:벡터화 객체’로 dict타입 반환
print(model.wv['python'])
word_vectors = model.wv
print('word_vectors.vocab: ', word_vectors.vocab) #key, value로 구성된 vocab obj
vocabs = word_vectors.vocab.keys()
print('vocabs: ', vocabs)
vocab_val = word_vectors.vocab.values()
print('vocab_val: ', vocab_val)
word_vectors_list = [word_vectors[v] for v in vocabs]
print('word_vectors_list:')
print(word_vectors_list)
# 각 key에 대한 벡터값
(8) 메소드
1) load(저장된 파일경로)
① 이전에 저장 한 Word2Vec모델 반환
② 반환 type: Word2Vec
2) init_sims( replace = True ): 필요없는 메모리 해제
3) save(저장할 파일 경로.model): 학습시킨 모델 저장. 저장한 모델은 load로 재사용 가능
4) LineSentence(source) - iterable타입
① source: 읽어올 파일경로나 문자열
② 한줄 단위로 읽어와서 띄어쓰기 기준으로 토큰화한 것을 list로 반환
fileName = 'news2.txt'
with open(fileName, mode='w', encoding='utf_8') as fw:
fw.write('\n'.join(result))
print('저장 성공!!')
# Word Embedding(단어를 수치화)의 일종으로 word2vec
from gensim.models import word2vec
genObj = word2vec.LineSentence(fileName) # LineSentence객체 생성
print(genObj) # <gensim.models.word2vec.LineSentence object at 0x0000022C7C734250>
for s in genObj:
print(s)
5) wv.similarity(단어1, 단어2): 두 단어를 넘겨주면 코사인 유사도 반환
6) model.wv.most_similar(positive=[단어들1], negative=[단어들2])
① positive=[단어들1]: 단어들1과 가까운(유사한) 단어들 반환
② negative=[단어들2]: 단어들2와 먼 단어들 반환
※ 코사인 유사도(Cosine Similarity)
n 두 벡터 간의 코사인 각도를 이용하여 구할 수 있는 두 벡터의 유사도를 의미
n 두 벡터의 방향이 완전히 동일한 경우에는 1
n 90°의 각을 이루면 0
n 180°로 반대의 방향을 가지면 -1
n 코사인 유사도는 -1 이상 1 이하의 값을 가지며 값이 1에 가까울수록 유사도가 높다고 판단

n 두 벡터 A, B에 대해서 코사인 유사도는 식

[참고] word2vec 관련 이론 정리 | Beomsu Kim (wordpress.com)
[참고] doc.mindscale.kr/km/unstructured/11.html
[참고] models.word2vec – Word2vec embeddings — gensim (radimrehurek.com)
[참고] 딥 러닝을 이용한 자연어 처리 입문 - WikiDocs
7. KoNLPy(코엔엘파이)
(1) 한국어 정보처리를 위한 파이썬 패키지
(2) 클래스
1) Okt(Open Korea Text)
2) 메캅(Mecab)
3) 코모란(Komoran)
4) 한나눔(Hannanum)
5) 꼬꼬마(Kkma)
(3) 사용하고자 하는 클래스 생성자로 생성 후 사용 => 클래스명 = 클래스()
(4) 형태소 분석: 클래스명.morphs(“문장”)
(5) 품사태깅: 클래스명.pos(“문장”, [stem = True/False])
1) stem = True: 원형 어근으로 출력 ex) 반가워요 => 반갑다. 받아 => 받다
2) default값은 False
(6) 명사추출: 클래스명.nouns(“문장”)
from konlpy.tag import Okt
okt = Okt()
#품사 태깅 - 모든 단어들의 각각의 종류를 보여줌 ('저자', 'Noun'), ('의', 'Josa'), ('허락', 'Noun'), ('을', 'Josa'),.....
print(okt.pos("저자의 허락을 받아 한국어로 번역해 전문 게재합니다. 가급적 직역하고 용어는 한국어와 영어를 병기했습니다. 본 블로그에도 관련 내용이 있다면 ‘본 블로그’ 표시를 하고 링크를 걸어두었습니다."))
print()
# stem = True: 원형어근으로 출력 ex) 반가워요 => 반갑다. 받아 => 받다
print(okt.pos("저자의 허락을 받아 한국어로 번역해 전문 게재합니다. 가급적 직역하고 용어는 한국어와 영어를 병기했습니다. 본 블로그에도 관련 내용이 있다면 ‘본 블로그’ 표시를 하고 링크를 걸어두었습니다.", stem=True))
print()
# 명사만 추출
print(okt.nouns("저자의 허락을 받아 한국어로 번역해 전문 게재합니다. 가급적 직역하고 용어는 한국어와 영어를 병기했습니다. 본 블로그에도 관련 내용이 있다면 ‘본 블로그’ 표시를 하고 링크를 걸어두었습니다."))
print()
# 모든 종류 다 나옴
print(okt.morphs("저자의 허락을 받아 한국어로 번역해 전문 게재합니다. 가급적 직역하고 용어는 한국어와 영어를 병기했습니다. 본 블로그에도 관련 내용이 있다면 ‘본 블로그’ 표시를 하고 링크를 걸어두었습니다."))
print()
(7) 문장분리: 유일하게 Kkma 패키지만 가능
형식)
Kkma = Kkma()
Kkma.sentences(“문장”)
from konlpy.tag import Kkma
Kkma = Kkma()
print(Kkma.sentences("저자의 허락을 받아 한국어로 번역해 전문 게재합니다. 가급적 직역하고 용어는 한국어와 영어를 병기했습니다. 본 블로그에도 관련 내용이 있다면 ‘본 블로그’ 표시를 하고 링크를 걸어두었습니다."))
print(Kkma.nouns("저자의 허락을 받아 한국어로 번역해 전문 게재합니다. 가급적 직역하고 용어는 한국어와 영어를 병기했습니다. 본 블로그에도 관련 내용이 있다면 ‘본 블로그’ 표시를 하고 링크를 걸어두었습니다."))
[참고] KoNLPy: Korean NLP in Python — KoNLPy 0.5.2 documentation
'Python' 카테고리의 다른 글
| 21. 데이터 시각화 (0) | 2021.05.07 |
|---|---|
| 20. Selenium (0) | 2021.05.07 |
| 19. schedule 모듈 (0) | 2021.05.07 |
| 18. json 모듈 (0) | 2021.05.07 |
| 17. BeautifulSoup (0) | 2021.05.06 |




