고정 헤더 영역
상세 컨텐츠
본문
1. matplotlib: ploting library. 그래프(차트) 생성을 위한 다양한 함수 지원 - import matplotlib.pyplot as plt
(1) 차트 용어

1) tick
① Axis의 값들
② tick은 숫자만 취급
③ tick의 값을 설정할 때는 순서가 있는 List타입과 Tuple타입 사용가능
=> List와 Tuple은 0번부터 시작하는 index가 부여됨
예를 들어 ['서울', '인천', '수원']인 경우에 서울은 0, 인천은1, 수원은 2인 index가 부여됨.
이 index로 tick값으로 처리
④ 순서가 없는 set 타입은 사용 불가
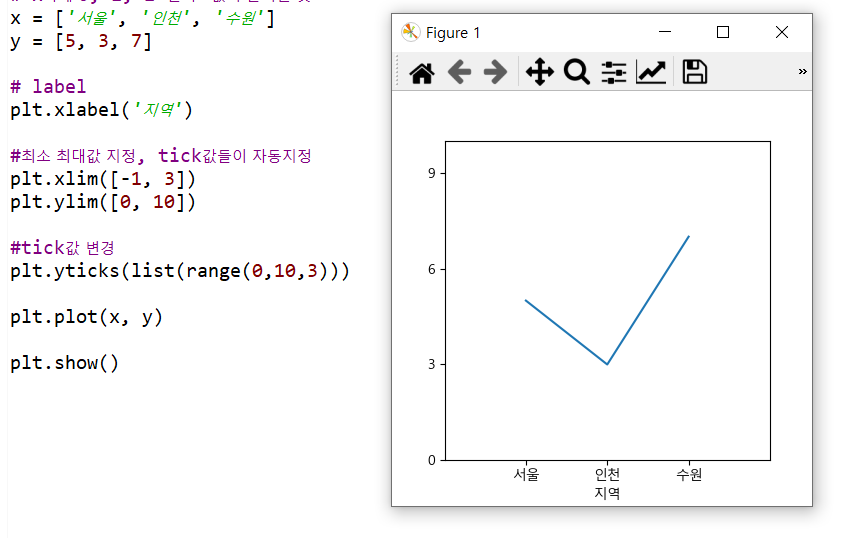
⑤ plt.xticks(값): x축 tick 설정
⑥ plt.yticks(값): y축 tick 설정
⑦ plt.xlim(범위): x축 tick을 범위 내에서 자동 지정
⑧ plt.ylim(범위): y축 tick을 범위 내에서 자동 지정
2) label
① plt.xlabel(‘이름’): x축 레이블 이름설정
② plt.ylabel(‘이름’): y축 레이블 이름설정
3) figure
① 기본 틀 마련
② plt.figure()
4) 범례: plt.legend([이름1, 이름2,…], loc=n): loc: 범례위치, 1~4는 사분면과 같다고 생각
5) 차트제목: plt.title('차트제목')
(2) 한글 깨짐 방지: plt.rc('font', family='malgun gothic')
(3) 음수 기호 깨짐 방지: plt.rcParams['axes.unicode_minus'] = False
(4) 메소드
1) plt.show()
① 차트 보여주기
② 차트를 n개 정의하고 마지막에 show메소드를 한번만 호출하면 하나의 figure에 n개의 차트가 겹쳐 보이게 됨.
③ 주피터에서는 show()대신에 매직command ‘% matplotlib inline’을 사용

2) plt. text( x , y , s): 데이터 좌표에서 x , y 위치의 좌표축에 텍스트 s 를 추가
① x, y: 텍스트를 배치 할 위치. 데이터 좌표
② s: 텍스트
3) plt.grid(True/False): 격자 표시 여부. 디폴트 값은 False
4) plt. axvline(x): 축에 수직선을 추가
5) axhline(y): 축을 가로 지르는 수평선을 추가
6) 차트 이미지 파일로 저장
1st. 차트 만들기
2nd. 이미지저장 선언: fig = plt.gcf()
3rd. 이미지 띄운 후: plt.show()
※ Django에서 저장할 때는 1st와 3rd 만 작업
4th. 이미지 저장: fig.savefig('파일경로/파일명.png')
※ Django에서는 프로젝트 명부터 찍어야 함
7) 이미지 파일 불러오기
① from matplotlib.pyplot import imread
② img = imread('파일명')
③ plt.imshow(img)
④ plt.show()
(5) 차트 종류
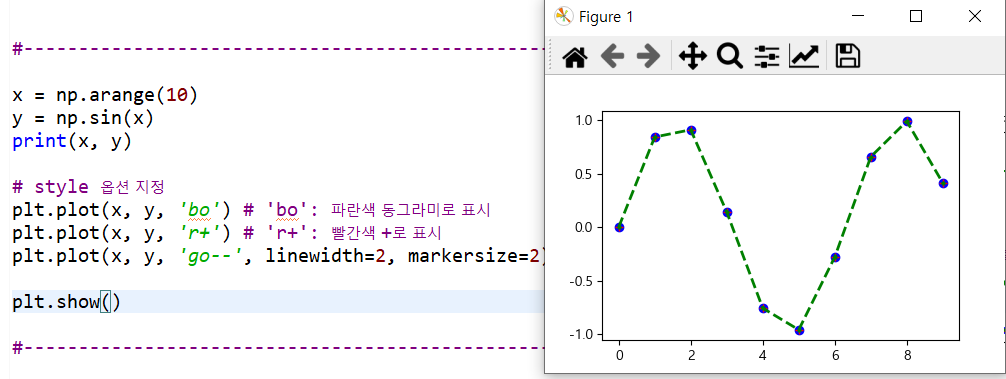
1) plot(x, y, [style])
① 기본값은 선 그래프
② style: 그래프 모양이나 색 설정
i. o: 원형 점 그래프
ii. --: 파선 그래프
iii. -: 직선 그래프
iv. s: 사각형 점 그래프
v. ‘r’ = ‘red’
ex) ‘go--’: 초록색으로 파선 위에 점으로 표시
vi. linewidth=n: 라인 두께
vii. markersize=n: 점의 크기
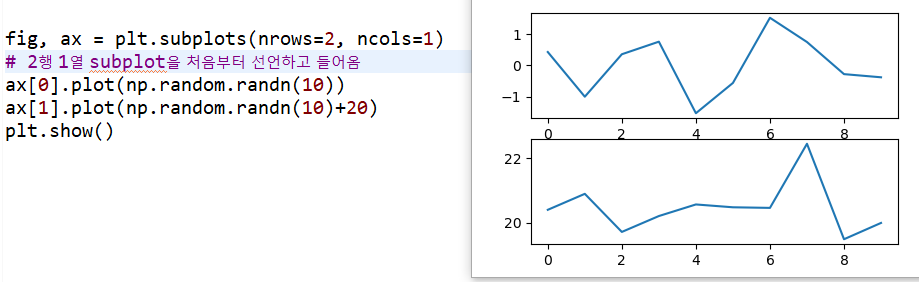
2) plt.subplot(n, m, k)/plt.figure().add_subplot(n, m, k)/ plt.subplots(nrows=n, ncols=m)
① figure에 n행 m열로 구역을 나누는 메소드
② k: 왼쪽에서부터 1번 오른쪽방향으로 진행, 그리고 다음줄로 넘어가는 순서
③ subplots를 변수로 정의해서 사용할 때는 반드시 두 개 변수 명 사용
import matplotlib.pyplot as plt
fig, ax = plt.subplots(4, 6)
print(fig)
print(ax.flat)
print(len(ax.flat))
for i, axi in enumerate(ax.flat):
axi.imshow(x_test[i].reshape(62,47), cmap='bone')
axi.set(xticks=[], yticks=[])
axi.set_ylabel(faces.target_names[pred[i]].split()[-1], color='black' if pred[i] == y_test[i] else 'red')
fig.suptitle('pred result', size=14)
plt.show()
<add_subplot(), 변수사용>

<subplot(), 변수 미사용> - subplot() 생성 -> 차트 정의 -> plt.show()

< subplots()>
④ Series, DataFrame을 매개변수로도 사용가능
<Series>

<DataFrame>

3) hist(data, bins=n, alpha=m): 히스토그램
① 히스토그램은 데이터프레임의 열 데이터 분포와 빈도를 살펴보는 용도로 자주 사용
② 도수분포표를 그래프로 나타낸 것
③ 가로축은 계급, 세로축은 도수 (횟수나 개수 등)
④ 일변량 그래프: 변수 1개로 만드는 그래프
⑤ bins = n: x축 간격을 n으로 조정
⑥ alpha = m: 투명도, 0 ≤ m ≤ 1, 값이 작아질수록 투명해짐

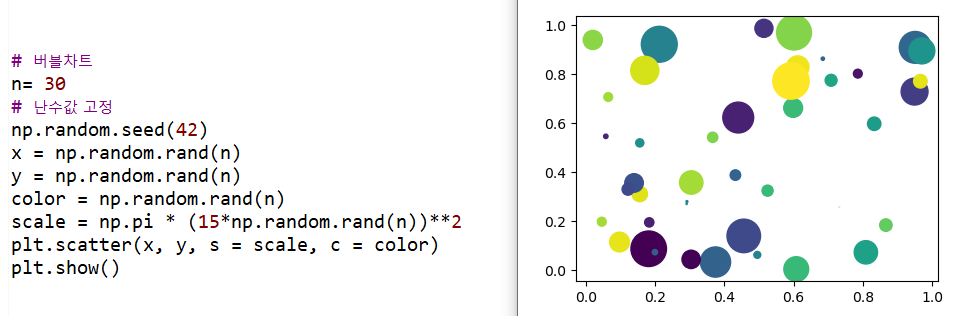
4) scatter(x, y, s = scale, c = color, alpha=m)
① 산점도 그래프
② 이변량 그래프: 변수 2개로 만드는 그래프
③ s
i. iterable한 데이터를 입력 시 마커마다 다른 크기 적용
ii. 상수로 입력 시 크기 고정
④ c
i. iterable한 데이터를 입력 시 마커마다 다른 색상 적용
ii. 상수로 입력 시 색상 고정

5) bar(), barh()
① 막대그래프: 범주가 있는 데이터 값을 직사각형의 막대로 표현하는 그래프
② bar(): 세로막대 그래프
③ barh(): 가로막대 그래프
④ plt.bar(x, values, width=w, align='edge'/’center’, color="색", edgecolor="색", linewidth=n, tick_label=literal type data, log=True/False, xerr=err, alpha=m)
i. width
a. 막대의 너비
b. 디폴트 값은 0.8
ii. align
a. tick과 막대의 위치를 조절
b. 디폴트 값은 ‘center’
c. align = ‘edge’: 막대의 왼쪽 끝에 x_tick이 표시
iii. color: 막대 색 지정
iv. edgecolor: 막대 테두리 색 지정
v. linewidth: 테두리 두께 지정
vi. tick_label: literal 타입으로 지정하면, tick에 literal 타입의 요소들을 순서대로 표시
vii. log=True: y축이 로그 스케일로 표시
viii. xerr/yerr: x값/y값의 데이터 포인트의 위/아래 대칭인 오차
ex) xerr = 3이라고하면 x값 기준 좌, 우로 3씩 총 6만큼 선으로 표시
yerr = 3이라고 하면 y값 기준 상, 하로 3씩 총 6만큼 선으로표시

6) plt.pie(ratio, labels=labels, labeldistance=m, autopct='%.1f%%', startangle=260, counterclock=False, explode==(0.2,0,0,0.3,0), shadow=True, colors=colors, wedgeprops=wedgeprops)
① 파이차트: 범주 별 구성 비율을 원형으로 표현한 그래프
② 이산형 데이터에 적합
③ autopct: 부채꼴 안에 표시될 숫자의 형식을 지정
④ labeldistance
⑤ label을 파이 안에 입력
⑥ 숫자가 커질수록 중심으로부터 멀리 입력
⑦ startangle
i. 부채꼴이 그려지는 시작 각도를 설정
ii. 디폴트 값: x축의 양의방향으로 0도
⑧ counterclock = False: 시계 방향 순서로 부채꼴 영역이 표시
⑨ explode
i. 부채꼴이 파이 차트의 중심에서 벗어나는 정도를 설정
ii. 반드시 파이의 개수와 순서를 맞춰서 설정해야함
⑩ shadow = True: 파이 차트에 그림자가 표시
⑪ colors
i. 각 영역의 색상 지정
ii. 리스트로 복수 개 지정가능
iii. 파이조각보다 적은 수의 색 지정 시 반복사용
⑫ wedgeprops
i. 부채꼴 영역의 스타일 설정
ii. wedgeprops dict의 ‘width’, ‘edgecolor’, ‘linewidth’ key를 이용해서 각각 부채꼴 영역의 너비 (반지름에 대한 비율), 테두리의 색상, 테두리 선의 너비를 설정
7) boxplot(a, b, c…, labels, palette)
① 박스그래프
i. x축에 이산형 변수, y축에 연속형 변수로 만드는 차트
ii. 다양한 통계수치 확인위해 자주 사용
iii. 전체 데이터로부터 얻어진 아래의 다섯 가지 요약 수치를 사용
a. 최소값
b. 제 1사분위 수 (Q1)
c. 제 2사분위 수 또는 중위수 (Q2)
d. 제 3사분위 수 (Q3)
e. 최대값
iv. 사분위 수는 데이터를 4등분한 지점을 의미합니다. 예를 들어, 제 1사분위 수는 전체 데이터 중 하위 25%에 해당하는 값이고, 제 3사분위 수는 전체 데이터 중 상위 25%에 해당하는 값입니다.
② a, b, c,…데이터 개수만큼 박스 만들어 짐

2. seaborn 라이브러리 - import seaborn as sns
(1) matplotlib기반으로 만들어진 라이브러리
(2) matplotlib보다 좀 더 세련되게 차트를 만들 수 있다.
(3) seaborn 제공의 dataset 불러오기: sns.load_dataset(‘데이터명’) => DataFrame으로 반환

(4) 인자(argument)
1) hue: 카테고리 지정
ex) hue = ‘who’: data의 사람 카테고리로 지정
(5) 차트종류
1) kdeplot(x1, [x2]): 밀집도
① 1개 데이터가 매개변수로도 들어간다면 곡선그래프로 밀집도를 표현
② 이차원 밀집도: 2개 데이터 매개변수
2) rugplot()
① 양탄자 그래프: 그래프 축에 동일한 길이의 직선을 붙여 데이터의 밀집도를 표현한 그래프
3) distplot(x)
① 히스토그램과 밀집도 그래프를 같이 그림
② hist = False: 히스토그램 제외
③ kde = False: 밀집도 그래프 제외
④ rug = True: 양탄자 그래프 포함
⑤ fit = stats.norm: 정규분포 그래프 함께 보여주기

4) countplot(x, data)
① x의 이산 값(개수)을 나타내는 그래프
② 숫자형 변수와 하나 이상의 범주형 변수의 관계
5) regplot(x, y, data, [fit_reg=True/False])
① 회귀선과 산점도그래프
② fit_reg=False: 회귀선 제외
6) joinplot(x, y, data, kind)
① 산점도와 히스토그램
② kind=’hex’: 산점도 모양을 육각형으로 지정
7) barplot(x, y, data)
① 바 그래프
② 숫자형 변수와 하나 이상의 범주형 변수의 관계
8) boxplot(x, y, data, palette)
① 박스 그래프
② 숫자형 변수와 하나 이상의 범주형 변수의 관계
③ palette: 박스의 색 지정
ex) palette='Paired': 은은한 색
9) violinplot(x, y, data)
① 박스 그래프는 다양한 통계수치를 확인하기 위해 자주 사용하지만 데이터 분산이 모호
② 이를 보완하기위해 커널 밀도를 추정한 바이올린 그래프 사용
③ 숫자형 변수와 하나 이상의 범주형 변수의 관계
10) pairplot(data, height, width)
① 관계그래프: 모든 변수의 상관관계를 보여주는 그래프
② 변수의 개수가 n개라면 (n×n)개의 그래프가 그려진다
③ 디폴트값은 대각선을 기준으로 위와 아래 그래프가 동일하게 그려진다
④ 따라서 각각에 필요한 그래프를 설정가능
i. map_upper(func)메소드: 대각선을 기준으로 위쪽에 그릴 그래프 지정
ii. map_lower(func)메소드: 대각선을 기준으로 아래쪽에 그릴 그래프 지정
iii. map_diag(func)메소드: 대각선을 중심으로 그릴 그래프 지정
※ 대각선 위쪽에 이차원 밀집도 그래프

11) 산점도 그래프
① relplot(x, y)
② scatterplot(x, y, data, marker)
12) heatmap(data): 밀도를 색으로 표현, 색이 진할수록 약한 상관관계

[참고] seaborn: statistical data visualization — seaborn 0.11.1 documentation (pydata.org)
'Python' 카테고리의 다른 글
| 22. 자연어 처리(Natural Language Processing: NLP) (0) | 2021.05.10 |
|---|---|
| 20. Selenium (0) | 2021.05.07 |
| 19. schedule 모듈 (0) | 2021.05.07 |
| 18. json 모듈 (0) | 2021.05.07 |
| 17. BeautifulSoup (0) | 2021.05.06 |




