고정 헤더 영역
상세 컨텐츠
본문
1. DataFrame
(1) 표 모양(2차원)의 자료구조, Series가 여러 개 합쳐진 형태.
(2) 형식: DataFrame(object, columns=[컬럼명], index=[row명])
(3) 행마다 자동으로 index 생성
(4) 각각의 컬럼이 Series가 됨
(5) 2차원 배열과의 차이점: 각 컬럼마다 type이 다를 수 있다
☞ dict의 key들이 DataFrame의 컬럼이 되는데 컬럼의 형태는 다양
# DataFrame: 표 모양(2차원)의 자료구조, Series가 여러 개 합쳐진 형태.
# 2차원 배열과 의 차이점: 각 컬럼마다 type이 다를 수 있다
from pandas import DataFrame
df = DataFrame()
data = {
'irum':['홍길동', '한국인', '신기해', '공기밥', '한가해'],
'juso':('역삼동', '신당동', '역삼동', '역삼동', '신사동'),
'nai':[23, 25, 33, 30, 35]
}
frame = DataFrame(data) # dict타입을 DataFrame으로 생성
print(frame)
è ‘irum’와 ‘nai’의 value는 리스트
è ‘juso’의 value는 Tuple
è 그래도 DataFrame 만들 수 있다
(6) columns와 index는 입력된 순서대로 DataFrame이 만들어진다
1) 순서는 다시 변경 가능 -> 변경하고 싶은 순서대로 다시 DataFrame을 정의하면 됨
2) 컬럼 추가 가능. 컬럼의 공간만 확보, 값은 NaN
from pandas import DataFrame
frame2 = DataFrame(data, columns=['irum', 'juso', 'nai', 'tel'], index = ['a', 'b', 'c', 'd', 'e'])
# 컬럼 추가(공간만 확보)
print(frame2)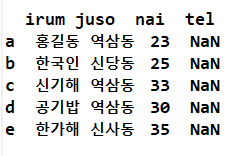
<obj_df = DataFrame(object, columns=[컬럼명], index=[row명])>
(7) 여러 개의 비교 조건문을 & (AND), 또는 | (OR) 로 연결해서 다수개의 조건을 AND, 또는 OR로 만족하는 행을 가져오고 싶을 경우 반드시 조건문에 (조건문) & (조건문), (조건문) | (조건문) 처럼 조건문에 괄호 ( ) 해주기
(8) 속성
1) 전치: 행과 열의 자리 바꿈 => obj_df.T
2) 데이터 크기 조회: obj_df.shape
3) value추출
① obj_df.values: numpy의 ndarray type으로 각 컬럼들이 추출, numpy의 2차원 array로 반환
i. obj_df.values[index1:index2]: index1이상 index2미만의 index의 값 추출
ii. obj_df.values[n, m]: n행 m열의 값 추출
② obj_df.컬럼명
i. 해당 컬럼의 값들을 index와 함께 추출
ii. type은 Series
iii. 속성으로 접근
③ obj_df[‘컬럼명’]
i. 해당 컬럼의 값들을 index와 함께 추출
ii. type은 Series
iii. dict형식으로 접근
(9) 행/열 추가
1) 값 추가: 보통 변수를 지정하여 값을 정의 <val = 값>
① 리스트, 튜플, Series타입
i. 리스트와 튜플은 index를 지정해서 값을 배정할 수 없으므로 index순서대로 전체를 입력
ii. Series는 특정 index만을 지정해서 값 배정 가능
② 문자열: 추가하고자 하는 컬럼의 모든 값을 동일하게 배정
2) 기존의 컬럼에 값 추가 또는 수정
① obj_df[컬럼명] = val
② obj_df.컬럼명 = val
3) 새로운 컬럼을 생성하면서 값 추가: obj_df[컬럼명] = val
2. DataFrame의 함수
(1) 함수.any(): 조건에 맞는 상황이 하나라도 있다면 함수 실행
ex) df.isnull().any(): df의 값들 중에 결측 치가 하나라도 있다면 True, 아니면 False
(2) obj_df.apply(함수): 함수를 실행하는 함수
df['genNum'] = df['gender'].apply(lambda g:1 if g =='남' else 2)
df['coNum'] = df['co_survey'].apply(lambda c:1 if c =='스타벅스' else 2 if c =='커피빈' else 3 if c =='이디야' else 4)
(3) map(함수, parameter)
1) 함수와 인자 값을 매핑하면서 데이터를 분배 처리
2) 리턴값 = 리스트
3) obj_df.set_index(컬럼명): 해당 컬럼 값들을 index로 설정
4) obj_df.rename(columns={기존 컬럼명:새로운 컬러명}): 컬럼명 변경
5) reindex(): 재색인
(4) ...으로 축약 안하고 전체 보여주는 옵션 설정
1) pd.set_option('display.max_rows', 500): 최대 줄 수 설정
2) pd.set_option('display.max_columns', 500): 최대 열 수 설정
3) pd.set_option('display.width', 1000): 표시할 가로의 길이
(5) 행/열 삭제
1) drop()
① 특정 행 삭제: obj_df.drop(index, [axis=0])
② 특정 열 삭제: obj_df.drop(컬럼명, axis=1)
2) dropna()
① NaN이 한개라도 포함된 행 삭제
i. obj_df = obj_df.dropna(how=’any’)
ii. obj_df = obj_df.dropna(axis = 'rows')
② 값이 전부 NaN인 행만 삭제: obj_df = obj_df.dropna(how=’all’)
③ NaN이 포함된 컬럼 삭제: obj_df = obj_df.dropna(axis = 'columns')
④ 해당 컬럼에서 NaN포함된 행 삭제: obj_df = obj_df .dropna(subset=[컬럼명])
(6) 정렬
1) sort_values()
① obj_df.sort_values(by=[컬럼1, 컬럼2…], ascending=True/False)
i. 지정한 컬럼의 값들을 기준으로 정렬
ii. ascending=True: 오름차순
iii. ascending= False: 내림차순
2) sort_index()
① obj_df.sort_index(axis=0, ascending=False): index기준 내림차순
② obj_df.sort_index(axis=1, ascending=True): 컬럼명 오름차순
3) obj_df.rank(axis = 0): 컬럼마다 ㄱ,ㄴ,ㄷ..순/1,2,3,..순/a,b,c...순으로 순위 매김
(7) 문자열 자르기
1) 문자열.strip()/lstrip()/rstrip()
2) Series([x.split()[n] for x in obj_df.컬럼명])
① 컬럼 값을 공백을 기준으로 문자 자른 후 n번째 값 추출
② n은 0부터 시작
from pandas import Series
import numpy as np
from pandas import DataFrame
print('문자열 자르기------------------')
print()
data = {
'juso':['강남구 역삼동', '중구 신당동', '강남구 대치동'],
'inwon':[22,23,24]
}
fr = DataFrame(data)
print(fr)
print()
result1 = Series([x.split()[0] for x in fr.juso])
result2 = Series([x.split()[1] for x in fr.juso])
print(result1)
print()
print(result2)
print()
print(result1.value_counts())
3) 외부에서 자료를 받을 경우 공백여부확인 방법 – 자료 가공작업
① obj_df.info()로 컬럼명 배치 보기
② 작업 전 공백 제거후에 작업 시작
import pandas as pd
human_df = pd.read_csv('https://raw.githubusercontent.com/pykwon/python/master/testdata_utf8/human.csv')
print(human_df.info())
print()
human_df = human_df.rename(columns=lambda x: x.strip())
print(human_df.info())
(8) bool처리
1) null 유무
① obj_df.isnull(): null이면 True, 아니면 False
② obj_df.notnull(): null이 아니면 True, 아니면 False

2) 결측치 확인
① True/False로 반환
② dataframe.isna()
i. NA, None, numpy.nan: True
ii. 그 외: False
③ dataframe.notna()
i. isna와 반대
ii. NA, None, numpy.nan: True
iii. 그 외: False
3) 특정 값 확인
① isin([값1, 값2…])
② 값1, 값2 존재 유무
③ 있으면 True, 아니면 False
※ obj_df[~obj_df[컬럼명].isin([a])]: obj_df에 특정 컬럼 값들 중 a를 제외한 값들로 다시 DataFrame 재구성
(9) 인덱싱
1) loc[조건]:
① 라벨 지원(행의 이름)
import pandas as pd
df = DataFrame(np.arange(12).reshape(4,3), index = ['1월', '2월', '3월', '4월'], columns = ['강남', '강북', '서초'])
print('\n복수 인덱싱 처리--------------------')
print('\nloc처리--------------------')
# 복수 인덱싱 - loc: 라벨 지원(행의 이름), iloc: 숫자 지원(index)
print(df.loc['3월', :]) # 3월 행의 모든 열 '3월': 라벨
print(df.loc['3월',]) # 3월 행의 모든 열
print()
print(df.loc[:'2월']) #2월이하의 행 출력
print()
print(df.loc[:'2월', ['서초']]) #2월행 이하의 서초만 출력
② 콤마가 없을 때는 조건에 맞는 행의 모든 열을 반환
print('연봉이 5000 이상인 영업부\n', df2.loc[(df2['연봉'] >= 5000) & (df2['부서명']=='영업부')])
2) iloc(): 숫자 지원(index)
import pandas as pd
df = DataFrame(np.arange(12).reshape(4,3), index = ['1월', '2월', '3월', '4월'], columns = ['강남', '강북', '서초'])
print('iloc---------------------')
print()
print(df.iloc[2]) # 2행 모든열 출력
print()
print(df.iloc[2,:]) #2행 모든열 출력
print()
print(df.iloc[:3]) #3행미만 행 출력
print()
print(df.iloc[:3, 2]) # 3행 미만의 2열 출력
print()
print(df.iloc[:3, 1:3]) # 3행 미만 1열,2열 출력
(10) 수학/통계
1) sum(): 합
① NaN합은 0
② obj_df.sum([axis = 0]): 같은 컬럼 값들 다 더함, 열 단위 합
③ obj_df.sum(axis = 1): 같은 행 값들 다 더함, 행 단위 합
2) 평균: obj_df.컬럼명.mean(axis =0/1, skipna = True/False) = obj_df[‘컬럼명’].mean(axis =0/1, skipna = True/False)
① 컬럼명은 생략가능
② axis =0: 행 단위 평균
③ axis =1: 열 단위 평균
④ skipna = True: NaN은 연산. 단, 계산 대상이 전부 NaN이면 결과도 NaN
⑤ skipna = False: NaN은 연산에서 제외
3) 표준편차: obj_df.컬럼명.std() = obj_df[‘컬럼명’].std()
print('평균가격: ',round(menu_df.price.mean(), 2), '원')
print('가격 표준편차(STDEV): ',round(menu_df.price.std(), 2), '원')
print('가격 표준편차(stdevp): ',round(np.std(menu_df.price), 2), '원')
(11) 정보확인
1) obj_df.describe(): 요약통계량

① unique값 확인: pd.unique(obj_df[컬럼명])
2) obj_df.info(): 구조확인(DataFrame만 확인 가능, Series는 오류발생)

3) obj_df.head(n): 앞에서부터 n개 행 보여주기
4) obj_df.tail(n): 뒤에서부터 n개 행 보여주기
5) len(obj_df): DataFrame의 행의 개수
(12) stack/unstack
1) obj_df.stack(): index기준으로 출력
2) obj_df.stack().unstack()
① stack()이 실행된 객체에 사용
② 다시 DataFrame으로 출력
(13) 범주화: pd.cut(x, bins, right = True, labels = None, include_lowest = False)
1) x: 연속형 변수를 갖는 객체
2) bins: 나눌 구간을 갖는 리스트 ex) bins에 5개 -> labels:4개
3) right: 오른쪽 닫힘(포함) 여부, (,]가 디폴트
4) labels: 각 구간의 이름 부여
5) include_lowest: 최소값 포함 여부
import pandas as pd
bins = [1, 20, 35, 60, 150]
labels = ["소년", "청년", "장년", "노년"]
df["Age_group"] = pd.cut(df['Age'], bins, labels = labels)
dfAge = df[~df['Survived'].isin([0])]
print(dfAge)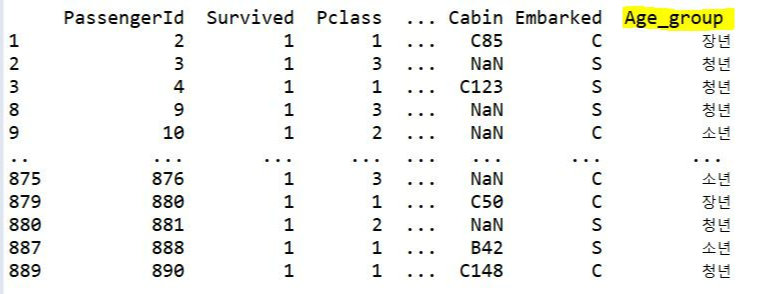

(14) 병합
① obj_df.merge(right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)
i. how
a. join 방법 (default는 inner join),
b. Outer Join은 'outer' / Inner Join은 'inner' / Left Join은 'left' / Right Join은 'right'
c. outer join: 두 DataFrame에서 모든 컬럼의 값들로 DataFrame 구성(합집합)
d. left inner join: 첫번째로 명시된 DataFrame의 컬럼 값들을 기준으로 DataFrame 구성
e. right inner join: 두번째로 명시된 DataFrame의 컬럼 값들을 기준으로 DataFrame 구성
ii. on
a. join할 key (같은 key 값을 갖을 경우)
b. join할 키가 다수인 경우 리스트 형식으로 전달
iii. left_on, right_on : 각 join할 key (서로 다른 key 값을 갖을 경우)
iv. left_index, right_index : join할 key가 인덱스일 경우
v. sort : 조인 키 정렬
② 공통 컬럼 有: pd.merge(df1, df2, on = 컬럼명, how='left'/’right’/’inner’/’outer’ left_on=df1의 컬럼명1, right_on=df2의 컬럼명2)
i. left_on=df1의 컬럼명1, right_on=df2의 컬럼명2: 조인 기준이 되는 공통된 컬럼 지정
③ 공통 컬럼 無: pd.merge(df1, df3, left_on=df1의 컬럼명1, right_on=df2의 컬럼명2)
import pandas as pd
import numpy as np
print('merge-----------------------')
df1 = pd.DataFrame({'data1':range(7), 'key':['b', 'b', 'a', 'c', 'a', 'a', 'b']})
print(df1)
print()
df2 = pd.DataFrame({'key':['a', 'b', 'd'], 'data2':range(3)})
print(df2)
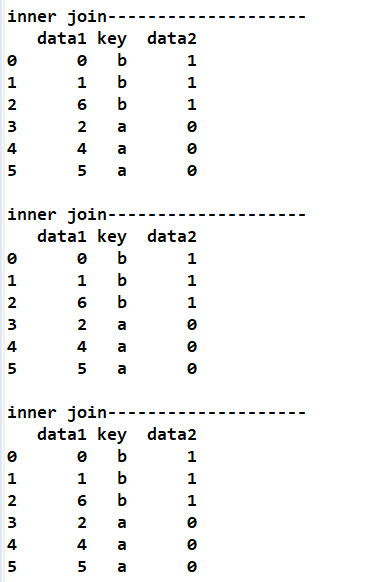
print('inner join--------------------')
print(pd.merge(df1, df2)) # 같은 키들을 추출해서 data1, data2값을 출력
print()
print('inner join--------------------')
print(pd.merge(df1, df2, on = 'key')) #inner join
print()
print('inner join--------------------')
print(pd.merge(df1, df2, how = 'inner')) #inner join
print('outer join--------------------')
print(pd.merge(df1, df2, how = 'outer')) #full outer join
print('left inner join--------------------')
print(pd.merge(df1, df2, on = 'key', how='left')) #left inner join
print('right inner join--------------------')
print(pd.merge(df1, df2, on = 'key', how='right')) #right inner join
print('\n공통컬럼이 없는 경우---------------------')
df3 = pd.DataFrame({'key2':['a', 'b','d'], 'data2':range(3)})
print(df3)
print(df1)
print('inner join--------------------')
print(pd.merge(df1, df3, left_on='key', right_on='key2'))
2) concat(): 단순히 두 DataFrame을 붙여 놓는 것
① 열단위로 처리(default)
i. pd.concat([df1, df2]))
ii. pd.concat([df1, df3], axis = 0))
② 행 단위로 처리: pd.concat([df1, df3], axis = 1)
print('concat-----------------------')
print(pd.concat([df1, df2]))
print()
print(pd.concat([df1, df3]))

print('열단위로 처리(default)')
print(pd.concat([df1, df3], axis = 0)) #열단위로 처리(default)
print('행단위로 처리')
print(pd.concat([df1, df3], axis = 1)) # 행단위로 처리
(15) 피벗테이블(pivot table)
1) 피벗(pivot)
① 데이터의 행렬을 재구성하여 그룹화 처리
② obj_df.pivot(행, 열, 값)
print('\n피벗 테이블: 데이터의 행렬을 재구성하여 그룹화 처리')
data = {'city':['강남', '강북', '강남', '강북'],
'year': [2000, 2001, 2005, 2002],
'pop': [3.3, 2.5, 3.0, 2]
}
df = pd.DataFrame(data)
print(df)
print()
print('pivot------------------')
print(df.pivot('city', 'year','pop')) #city, year별 pop의 평균
print()
print(df.set_index(['city', 'year']).unstack()) #기존의 행의 인덱스를 제거하고 처번째 인덱스 설정
print()
print(df.pivot('city', 'year','pop'))
print()
print(df['pop'].describe())
2) obj_df.groupby([컬럼명1, 컬럼명2…….])
① 컬럼명을 기준으로 그룹화하여 DataFrame 생성
② 컬럼명1, 컬럼명2…가 행이 되는 기준이 된다.
ex) df.groupby(['city','year']): city별 년도가 나누어진다.

print('groupby------------------')
hap = df.groupby(['city'])
print(hap.sum())
print()
print(df.groupby(['city']).sum())
print()
print(df.groupby(['city','year']).sum())
print()
print(df.groupby(['city','year']).mean())
③ 그룹함수
i. count(): 그룹별 항목의 값의 개수(NaN제외)
print('groupby----------------')
print(df2.groupby(['성별', '직급'])['직원명'].count())
ii. sum(): 그룹별 항목의 값의 합(NaN제외)
iii. mean(): 그룹별 항목의 값의 평균(NaN제외)
iv. median(): 그룹별 항목의 값의 중간값(NaN제외)
v. var(): 그룹별 항목의 값의 분산
vi. std(): 그룹별 항목의 값의 표준편차
vii. min(), max(): 그룹별 항목의 값의 최소값, 최대값
viii. prod(): 그룹별 항목의 값의 곱(NaN제외)
ix. agg([문자열1, 문자열2…])
a. 그룹별 항목의 값에 함수 적용
b. 위 그룹함수들을 소괄호 빼고 문자열로 입력
c. 복수 개 함수 적용 가능
d. 사용자 정의 함수 적용 가능
e. 복수 개의 함수를 적용할 때는 리스트 형식으로 매개변수 입력

3) pivot_table: pivot, groupby의 중간적 성격의 함수
① obj_df. .pivot_table(values=[컬럼명], index = [컬럼명], columns=[컬럼명], aggfunc=[함수]. margins=True/False, fill_value =a)
i. values, index, columns에 컬럼명은 복수 개 가능
ii. index값을 하나만 지정하면 나머지 값들 전부를 컬럼으로 만들고 지정한 index를 기준으로 분류하여 평균 값 출력
iii. aggfunc=함수
a. values를 계산할 함수
b. 디폴트는 평균(np.mean)
c. 복수 개 지정가능
iv. margins: aggfunc에 의해 계산된 값을 행 추가, 열 추가로 명시 여부
a. True이면 All이라는 컬럼명, index명으로 추가
b. False가 기본 값, 추가 없음
c. 계산 대상들 중에서 하나가 NaN이라면 다른 하나의 값으로 출력
v. fill_value =a: NaN을 a로 대체
print('**pivot, groupby의 중간적 성격의 함수: pivot_table**')
print(df)
print()
print(df.pivot_table(index = ['city']))
print()
print(df.pivot_table(index = ['city'], aggfunc=np.mean))
#aggfunc=np.mean를 안준 위의 것과 같은 결과
print(df.pivot_table(index = ['city'], aggfunc=[len, np.sum])) 
# city별 pop의 평균, aggfunc=np.mean 준것과 같은 값
print(df.pivot_table(values=['pop'], index = 'city')) 
print(df.pivot_table(values=['pop'], index = 'city', aggfunc=len))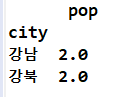
print(df.pivot_table(values=['pop'], index = ['year'], columns=['city']))
print(df.pivot_table(values=['pop'], index = ['year'], columns=['city'], margins=True))
print()
print(df.pivot_table(values=['pop'], index = ['year'], columns=['city'], margins=True, fill_value =0))
(16) 컬럼 값을 분류하여 개수 구하기: obj_df[‘컬럼’].value_counts()
(17) 타입 변경
1) obj_df[컬럼명].toarray()/tolist(): 해당 컬럼을 numpy의 array/list타입으로 변경
2) obj_df.astype({"컬럼명":"타입"})
df = df.astype({"최저기온":"int"})
print(df.info())
3) obj_df.astype("타입")

※ 숫자형태의 문자열이나 boolean형의 데이터를 int형으로 바꿀 때는 바꾸려는 대상에 숫자 1을 곱하면 자동 변환 가능
3. File I/O
(1) 파일 읽어 오기
1) 함수: DataFrame으로 출력
① read_csv(경로, header=None, names=[컬럼명], index_col= , encoding = , chunksize = n, dtype={컬럼명:데이터형}, usecols=[컬럼명/컬럼 순서번호])
i. header=None: 테이블 첫번째 제목 행 제외, index로 대체(0부터 시작)
ii. names: 컬럼명 지정, 여러 개일 때 리스트 형식
iii. index_col: 컬럼들 중에 하나를 행으로 지정
iv. chunksize = n
a. 파일이 너무 큰 경우 행을 n개씩 나눠서 읽기
b. n: 정수
v. dtype={dict형}
a. 컬럼 값의 데이터 유형을 지정
b. dict형으로 명령
vi. usecols=[컬럼명/컬럼 순서번호]: 특정 컬럼만 추출
import pandas as pd
sales_data = pd.read_csv('https://raw.githubusercontent.com/pykwon/python/master/testdata_utf8/tsales.csv', dtype={'YMD':'object'})
print(sales_data.info())
② read_table(경로, , sep= , skiprows= , encoding =)
i. sep: 분리 기준 - 콤마, '\s+'(한 개이상의 공백)
ii. 통째로 읽어 오기 때문에 반드시 sep정의
iii. skiprows: 제외할 행의 index. 여러 개일 때는 리스트 형식
③ read_fwf(경로, encoding = width=( ) , names=[컬럼명])
i. width: 문자열이 공백 없이 모두 붙어있을 자리수로 분리
ex) width=(10,3,5): 왼쪽에서부터 10자리, 3자리, 5자리로 분리
2) excel파일 읽기
① 파일 열기: ex = pd.ExcelFile('파일명.xlsx')
② 읽기
i. pandas함수: exf.parse('파일의 sheet명')
※ sheet명 확인: ex.sheet_names
ii. python함수 혼용: pd.read_excel(open('파일명.xlsx', 'rb/wb'), sheet_name='sheet명')
a. rb: binary로 읽기모드
b. rw: binary로 쓰기모드
(2) 파일로 저장
1) 파일로 저장하기 전에는 DataFrame으로 변환하기
2) csv파일로 저장
① to_csv('파일명.csv', sep= , index = True/False, header=True/False)
i. 색인 포함여부
ii. header 포함여부
3) excel파일로 저장
① wr = pd.ExcelWriter('저장할 파일명.xlsx', engine='xlsxwriter')
② obj_df.to_excel(wr, sheet_name='지정할 sheet명')

(3) db
# localdb: sqlite - db자료 <-> DataFrame
# Django가 아니라서 ORM을 사용하지 못한다
import sqlite3
import pandas as pd
sql = "create table if not exists test(product varchar(10), maker varchar(10), weight real, price integer)"
conn = sqlite3.connect(':memory:') # ram
conn.execute(sql)
data = [('mouse','sam',12.5,6000),('keyboard','lg',502.0,86000)] # 리스트안에 튜플로 한 세트씩 입력
stmt = "insert into test values(?, ?, ?, ?)"
conn.executemany(stmt, data) # 한번에 값 많이 넣을 때
conn.commit()
data1 = ('연필', '모나미', 3.5, 500)
conn.execute(stmt, data1)
conn.commit()
1) db자료를 DataFrame에 저장
① cursor.fetchall() 사용
# 1. DataFrame에 저장 - cursor.fetchall() 이용
cursor = conn.execute("select * from test")
rows = cursor.fetchall()
for a in rows:
print(a)
#df1 = pd.DataFrame(rows, columns=['product','maker','weight','price'])
df1 = pd.DataFrame(rows, columns=list(zip(*cursor.description))[0])
print(df1)
print('cursor.description\n', cursor.description)
print('type(cursor.description)\n', type(cursor.description)) # 튜플안에 요소들도 튜플
print('*cursor.description\n', *cursor.description) # 요소들 
# cursor사용 후 항상 close
cursor.close()
② pd.read_sql사용
i. pd.read_sql(sql문, 연결객체)
a. sql문 실행
b. DataFrame으로 반환
ii. obj_df.to_html(): DataFrame을 html의 테이블로 생성하는 코드
# 2. DataFrame에 저장 - pd.read_sql이용
df2 = pd.read_sql("select * from test", conn) # sql문, 연결객체
print(df2)
print(df2.to_html())
③ DataFrame의 자료를 db로 저장
i. obj_df.to_ sql(테이블명, 연결객체, if_exists='append', index = None): sql문장으로 변환 후 저장
# DataFrame의 자료를 db로 저장
data = {'irum':['신선해','신기해','신기한'],
'nai':[22, 25, 27]}
frame = pd.DataFrame(data)
conn = sqlite3.connect('test.db')
frame.to_sql('mytable', conn, if_exists='append', index = None) # sql문장으로 변환후 저장
df3 = pd.read_sql("select * from mytable", conn)
print(df3)
4. 교차테이블(교차표)
(1) 행과 열로 구성된 교차표로 결과(빈도수) 요약
(2) pd.crosstab([행1, 행2…], [열1, 열2…], rownames=[ ], colnames=[ ], margine=True/False)
(3) margine=True: 각 행과 열의 소계 계산
(4) 반환 타입은 DataFrame
# 교차 테이블(교차표): 행과 열로 구성된 교차표로 결과(빈도수) 요약
import pandas as pd
# 인구통계 dataset 읽기
des = pd.read_csv('https://raw.githubusercontent.com/pykwon/python/master/testdata_utf8/descriptive.csv')
print(des.info())
print()
# 5개 칼럼만 선택하여 data frame 생성
data = des[['resident','gender','age','level','pass']]
print(data[:5])
# 지역과 성별 칼럼 교차테이블
table = pd.crosstab(data.resident, data.gender)
print('지역과 성별 칼럼 교차테이블\n', table)
print()
# 지역과 성별 칼럼 기준 - 학력수준 교차테이블
table = pd.crosstab([data.resident, data.gender], data.level)
print('지역과 성별 칼럼 기준 - 학력수준 교차테이블\n', table)
print(type(table))
5. 시각화
(1) matplotlib.pyplot 모듈의 show()메소드와 함께 사용
(2) scatter_matrix(data, diagonal=)
1) from pandas.plotting import scatter_matrix
2) 관계그래프: 모든 변수의 상관관계를 보여주는 그래프
3) 변수의 개수가 n개라면 (n × n)개의 그래프가 그려진다
4) 디폴트 값은 대각선을 기준으로 위와 아래 그래프가 동일하게 그려진다
5) diagonal=
① kde: 밀도곡선
② hist: 히스토그램
from pandas.plotting import scatter_matrix
attr = ['친밀도', '적절성', '만족도']
scatter_matrix(df[attr], figsize=(10, 6))
plt.show()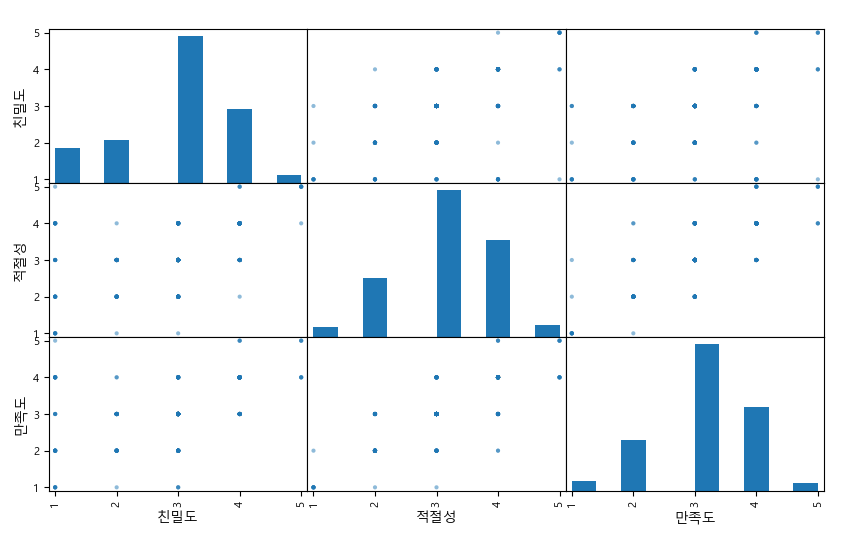
(3) obj_df.plot(kind = 그래프 종류)
1) obj_df.plot(kind = ‘bar’/’barh’, title , stacked=True/False) = obj_df.plot.bar(rot=n)
① 세로 막대 그래프/가로막대 그래프
② stacked=True: 스택형 막대그래프

③ obj_df.plot.bar(rot=n)는 부분데이터만 그래프 그릴 때 사용가능
ex) df[:5].plot.bar(rot=2)
④ rot는 x-tick의 회전 각도 나타냄
2) obj_df.plot(kind = ‘box’): 박스 그래프
df.plot(kind='box', x='만족도', y='적절성')
plt.show()
6. 시계열 데이터
(1) datetime 오브젝트
1) 날짜와 시간을 처리하는 등의 다양한 기능을 제공
2) 날짜를 처리하는 date 오브젝트, 시간 처리하는 time 오브젝트, 날짜와 시간을 모두 처리하는 datetime 오브젝트 등 포함
3) 시간 차이 계산 가능 최근 날짜 – 이전날짜 = 차이를 일수, 시간으로 반환
4) 생성자 datetime(y,M,d,h,m,s): yyyy-MM-dd hh:mm:ss 형식으로 변환
5) 메소드 from datetime import datetime
① 현재 시간 출력
i. datetime.now()
ii. datetime.today()
② datetime 오브젝트로 변환: pd.to_datatime(변환 대상, format=’날짜형식’)
[참고] Python 날짜/시간을 문자열로 만들기 위한 규칙 정리 - GoniGoni!
③ 출력 형태 설정: strftime(‘날짜형식’)

④ read_csv(parse_dates=[‘컬럼명’]): 파일을 읽어올 때 미리 해당 컬럼을 datetime타입으로 변환
⑤ 년, 월, 일 출력
i. 값.year/ 값.month/ 값.day
ii. 컬럼명.dt.year/ 컬럼명.dt. month / 컬럼명.dt. day => 정수형 반환
⑥ date_range(start=’시작날짜’, end=’마지막날짜’, freq=’시간주기’)
i. 일정 기간 사이의 시간 인덱스(DatetimeIndex) 자료형 생성
ii. 날짜, 시간을 index로 지정하면 원하는 시간데이터를 바로 추출 가능
import pandas as pd
from datetime import datetime
data = pd.read_csv('../testdata/weather.csv')
print(data.head())
head_range = pd.date_range(start='2016-11-01', end='2016-11-05', name='date')
print(head_range)
weather = data.head()
weather.index = weather.Date
weather.reindex(head_range)
print(weather)
iii. freq의 속성 값: 시간주기
|
시간주기 |
설명 |
|
B |
평일만 포함 |
|
C |
사용자가 정의한 평일만 포함 |
|
D |
달력 일자 단위 |
|
W |
주간 단위 |
|
M |
월 마지막 날만 포홤 |
|
SM |
15일과 월 마지막날만 포함 |
|
BM |
M 주기의 값이 휴일이면 제외하고 평일만 포함 |
|
CBM |
BM에 사용자 정의 평일만 적용 |
|
MS |
월 시작일만 포함 |
|
SMS |
월 시작일과 15일만 포함 |
|
BMS |
MS 주기의 값이 휴일이면 제외하고 평일만 포함 |
|
CBMS |
BMS에 사용자 정의 평일을 적용 |
|
Q |
3, 6, 9, 12월 분기 마지막 날만 포함 |
|
BQ |
3, 6, 9, 12월 분기 마지막 날이 휴일이면 제외하고 평일만 포함 |
|
QS |
3, 6, 9, 12월 분기 시작일만 포함 |
|
BQS |
3, 6, 9, 12월 분기 시작일이 휴일이면 제외하고 평일만 포함 |
|
A |
년의 마지막 날만 포함 |
|
BA |
년의 마지막날이 휴일이면 제외하고 평일만 포함 |
|
AS |
년의 시작일만 포함 |
|
BAS |
년의 시작일이 휴일이면 제외하고 평일만 포함 |
|
BH |
평일을 시간단위로 포함(09:00 ~ 16:00) |
|
H |
시간 단위로 포함(00:00 ~ 00:00) |
|
T |
분 단위 포함 |
|
S |
초 단위 포함 |
|
L |
밀리초 단위 포함 |
|
U |
마이크로초 단위 포함 |
|
N |
나노초 단위 포함 |
<freq=’B’: 기간 중 평일인 날짜만 추출>
print(pd.date_range('2021-01-01', '2021-01-31', freq='B' ))
'Python' 카테고리의 다른 글
| 18. json 모듈 (0) | 2021.05.07 |
|---|---|
| 17. BeautifulSoup (0) | 2021.05.06 |
| 16. pandas - (1) 개요, Series (0) | 2021.05.01 |
| 15. 멀티스레드, 멀티프로세스 (0) | 2021.05.01 |
| 14. 소켓(Socket) (0) | 2021.05.01 |




