고정 헤더 영역
상세 컨텐츠
본문
1. 개요
(1) 고수준의 자료구조(Series, DataFrame)를 지원
(2) 축약연산, 누락된 데이터 처리, sql query, 데이터 조작, 인덱싱, 시각화 등 다양한 기능
(3) numpy기반
(4) import pandas as pd
2. Series
(1) 일련의 데이터를 기억할 수 있는 1차원 배열과 같은 자료구조로 명시적인 색인(index)을 갖는다.
(2) index는 0부터 시작
(3) 형식: Series(object, index = [ind1, ind2, …])
1) object요소의 타입이 혼용되어 있을 경우 문자열>실수(float)>정수(int) 순으로 지정됨
2) 단, object에서 set{}타입은 사용불가
=> index를 갖기 때문에 순서가 있어야 한다. but set타입은 순서가 없다.
3) object가 dict타입일 때는 dict의 key가 Series의 index가 된다.
4) index = [ind1, ind2, …]는 별도 지정 가능하고, 생략하면 자동부여 된다.
<obj = Series(object, index = [ind1, ind2, …])>
(4) 속성
1) obj.values: Series의 값 추출, numpy의 array로 반환
2) obj.index: Series의 index와 dtype을 추출
3) obj.name: Series의 이름 지정
(5) 슬라이싱: index를 입력한 순서대로 출력됨
1) 해당 index의 값을 추출
① obj[‘index명1’]
② obj[index]
2) 해당 index와 값들을 추출
① obj[[‘index명1’, ‘index명2’…]]
② obj[[‘index1’, ‘index2’…]]
3) index1과 index2포함 그 사이에 있는 index들과 값들을 추출
① obj[[‘index명1’ : ‘index명2’]]
② obj[[‘index1’ : ‘index2’]]
4) True/False 반환
① 값에 대한 조건 ex) obj > 0 -> obj의 각각의 값이 0보다 크면 True, 아니면 False
② index에 대한 조건 ex) 'a' in obj -> obj의 index중에서 a가 있으면 True, 아니면 False
from pandas import Series
import numpy as np
obj1 = Series([3, 7, -5, 4])
print(obj1, type(obj1)) # dtype: int64 <class 'pandas.core.series.Series'>
# index 요소값 : index는 0부터 시작
# 0 3
# 1 7
# 2 -5
# 3 4
obja = Series([3, 7, -5, '4'])
print(obja, type(obja)) # dtype: object <class 'pandas.core.series.Series'>
objb = Series([3, 7, -5, 4.5])
print(objb, type(objb)) # dtype: float64 <class 'pandas.core.series.Series'>
objc = Series((3, 7, -5, 4))
print(objc, type(objc)) # dtype: int64 <class 'pandas.core.series.Series'>
"""
obj5 = Series({3, 7, -5, 4})
print(obj5, type(obj5)) # 집합형은 순서가 없어서 index부여 불가, 그래서 에러발생
"""
print()
obj2 = Series([3, 7, -5, 4], index = ['a', 'b', 'c', 'd']) #색인 지정
print(obj2)
print(sum(obj2), np.sum(obj2), obj2.sum()) # 파이썬 함수, numpy함수, 판다스 함수
#pandas는 numpy함수를 기본적으로 계승해서 사용
print()
print(obj2.values)
print(obj2.index)
from pandas import Series
import numpy as np
#슬라이싱
print('슬라이싱----------------------')
print(obj2['a'])
print()
print(obj2[['a']])
print()
print(obj2[['a', 'b']])
print()
print(obj2['a':'c'])
print()
print(obj2[2])
print()
print(obj2[1:4])
print()
print(obj2[[2,1]])
print()
print(obj2 > 0)
print()
print('a' in obj2)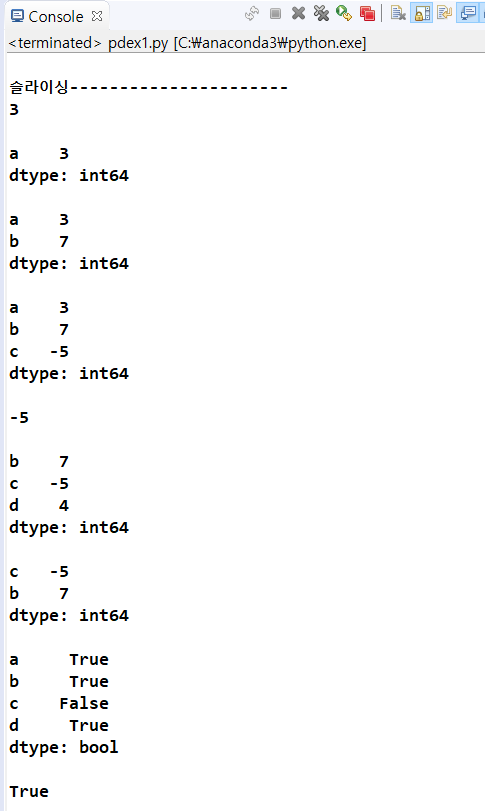
from pandas import Series
import numpy as np
print('\ndict 타입으로 Series 생성가능')
names = {'mouse':5000, 'keyboard':25000, 'monitor':550000}
print(names)
obj3 = Series(names)
print(obj3, ' ', type(obj3)) # dict타입의 key가 Series의 index역할을 함
print(obj3['mouse'])
obj3.name = '상품가격' #series객체의 이름을 부여
print(obj3)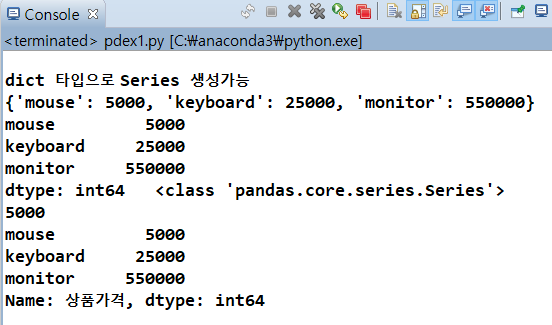
(6) 함수
① obj.reindex(object, [fill_value = A or method = 방법])
i. object에는 리스트나 튜플타입
ii. index의 순서를 재배치하거나 새로운 index를 추가 가능
iii. 재배치하는 경우에는 값들도 같이 따라서 변경됨
iv. 추가하는 경우 별도의 값에 대한 지정이 없을 경우 NaN으로 지정
② 새로운 index에 대한 값 지정
i. fill_value = A: 모든 값을 A로 채움
ii. method: 값을 채우는 방법
a. 대응 값이 없는 경우는 이전 값으로 채움, 0번째는 이전 값이 없으므로 NaN
ü method = ‘ffill’
ü method = ‘pad’
b. 대응 값이 없는 경우는 다음 값으로 채움, 마지막에는 다음 값이 없으므로 NaN
ü method = ‘bfill’
ü method = ‘backfill’
(7) 연산
1) index가 같은 값끼리 연산가능
2) 일치하는 index가 없을 경우 NaN
3) obj1 + obj2 = obj1.add(obj2)
from pandas import Series
import numpy as np
s1 = Series([1, 2, 3], index = ['a', 'b', 'c'])
s2 = Series([4, 5, 6, 7], index = ['a', 'b', 'd', 'c'])
print(s1)
print(s2)
print()
print(s1 + s2)
print()
print(s1.add(s2))
print()
print(s2.add(s1))
'Python' 카테고리의 다른 글
| 17. BeautifulSoup (0) | 2021.05.06 |
|---|---|
| 16. pandas - (2) DataFrame (0) | 2021.05.02 |
| 15. 멀티스레드, 멀티프로세스 (0) | 2021.05.01 |
| 14. 소켓(Socket) (0) | 2021.05.01 |
| 13. 원격(remote) db연동 – MariaDB (0) | 2021.04.29 |




