고정 헤더 영역
상세 컨텐츠
본문
대표적인 파이썬 ML 라이브러리
특징
1. 쉽고 가장 파이썬스러운 API 제공
2. 머신러닝을 위한 매우 다양한 알고리즘과 개발을 위한 편리한 프레임워크와 API 제공
3. 오랜기간 실전 환경에서 검증되었으며, 매우 많은 환경에서 사용되는 성숙한 라이브러리
설치
1. Anaconda를 설치하면 기본적으로 사이킷런도 함께 설치됨
2. 별도 설치시엔 pip와 conda 명령어를 통해 설치
3. conda 명령어로 설치 시엔 사이킷런 구동에 필요한 넘파이나 사이파이 등의 다양한 라이브러리를 동시 설치가 가능
용어정리
1. 하이퍼 파라미터
(1) 머신러닝 알고리즘별 최적의 학습을 위해 직접 입력하는 파라미터들을 통칭
(2) 알고리즘의 성능을 튜닝
2. Estimator 클래스
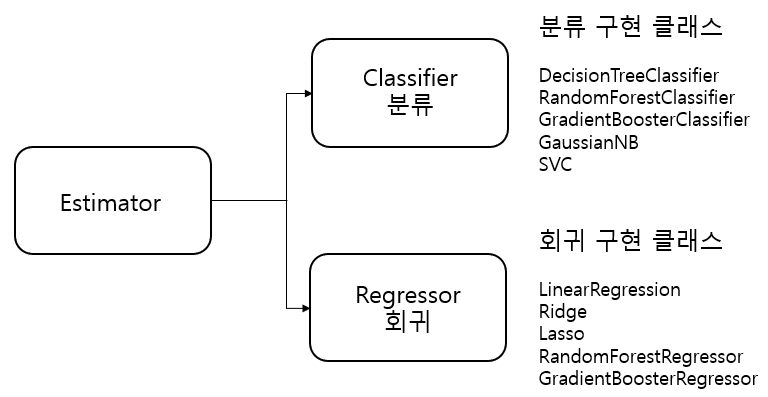
(1) 지도학습의 모든 알고리즘(분류, 회귀 등)을 구현한 클래스를 통칭
(2) 메서드
1) fit(): ML모델 학습
2) predict(피처): 학습된 모델의 예측결과 반환
비지도학습 메서드
1. fit(): 지도학습의 fit()과 같은 학습을 의미하는 것이 아니라 입력 데이터의 형태에 맞춰 데이터를 변환하기 위한 사전 구조를 맞추는 작업
2. transform(): fit()으로 변환을 위한 사전 구조를 맞추면 이후 입력 데이터의 차원 변환, 클러스터링, 피처 추출 등 실제 작업 수행
3. fit_transform(): fit()과 transform()을 하나로 결합한 메서드
주요 모듈
| 분류 | 모듈명 | 설명 |
| 예제 데이터 | sklearn.datasets | 사이킷런에 내장되어 예제로 제공하는 데이터 세트 |
| 피처 처리 | sklearn.preprocessing | 데이터 전처리에 필요한 다양한 가공 기능 제공(문자열을 숫자형 코드 값으로 인코딩, 정규화, 스케일링 등) |
| sklearn.feature_selection | 알고리즘에 큰 영향을 미치는 피처를 우선순위대로 셀렉션 작업을 수행하는 다양한 기능 제공 | |
| sklearn.feature_extraction | 텍스트 데이터나 이미지 데이터의 벡터화된 피처를 추출하는데 사용 ex) 텍스트 데이터에서 Count Vectorizer나 Tf-ldf vectorizer 등을 생성하는 기능 제공 sklearn.feature_extraction.text 모듈: 텍스트 데이터의 피처 추출 지원 API 제공 sklearn.feature_extraction.image 모듈: 이미지 데이터의 피처 추출 지원 API 제공 |
|
| 피처 처리 & 차원 축소 | sklearn.decomposition | 차원 축소와 관련한 알고리즘을 지원하는 모듈 PCA, NMF, Truncated SVD 등을 통해 차원 축소 기능을 수행 |
| 데이터 분리, 검증 & 파라미터 튜닝 | sklearn.model_selection | 교차 검증을 위한 학습용/테스트용 분리. 그리드 서치(Grid Search)로 최적 파라미터 추출 등의 API 제공 |
| 평가 | sklearn.metrics | 분류, 회귀, 클러스터링, 페어와이즈(Pairwise)에 대한 다양한 성능 측정 방법 제공 |
| ML 알고리즘 | sklearn.ensemble | 앙상블 알고리즘 제공 |
| sklearn.linear_model | 회귀 관련 알고리즘 지원 SGD(Stochastic Gradient Descent) 관련 알고리즘 제공 |
|
| sklearn.naive_bayes | 나이브베이즈 알고리즘 제공 가우시안NB, 다항분포NB 등 |
|
| sklearn.neighbors | 최근접 이웃 알고리즘 제공(K-NN) | |
| sklearn.svm | 서포트 벡터 머신 알고리즘 제공 | |
| sklearn.tree | 의사결정 트리 알고리즘 제공 | |
| sklearn.cluster | 비지도 클러스터링 알고리즘 제공 k-means, 계층형, DBSCAN |
|
| 유틸리티 | sklearn.pipeline | 피처 처리 등의 변환과 ML 알고리즘 학습, 예측 등을 함께 묶어서 실행할 수 있는 유틸리티 제공 |
내장된 예제 데이터 셋
1. 분류, 회귀를 연습하기 위한 예제용도의 데이터 셋
| 용도 | API명 | 설명 |
| 분류 | datasets.load_digits() | 0에서 9까지 숫자 이미지 픽셀 데이터 셋 |
| datasets.load_breast_cancer() | 위스콘신 유방암 피처들과 악성/음성 레이블 데이터 셋 | |
| datasets.load_iris() | 붓꽃에 대한 피처를 가진 데이터 셋 | |
| 회귀 | datases.load_boston() | 미국 보스턴의 집 피처들과 가격에 대한 데이터 셋 |
| datasets.load_diabetes() | 당뇨 데이터 셋 |
※ fetch 계열의 명령은 데이터의 크기가 커서 패키지에 처음부터 저장되어 있지 않고 인터넷에서 다운로드 경로로 불러들여 사용
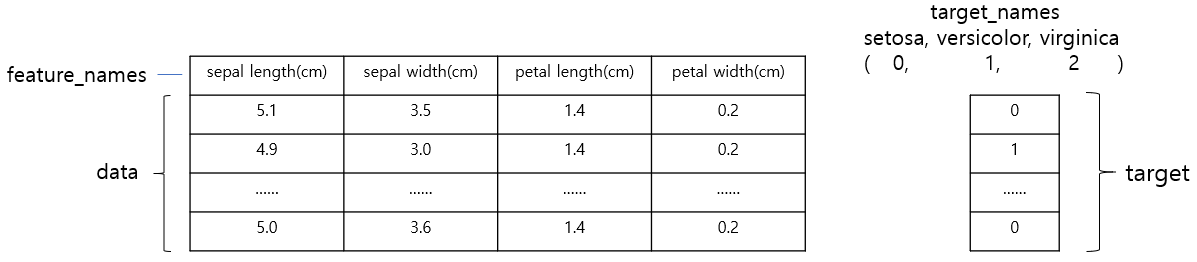
(1) 데이터 셋의 API의 반환 결과는 sklearn.utils.Bunch 클래스
(2) Bunch 클래스 딕셔너리(dict) 자료형과 유사
(3) 데이터 셋의 key: data, target, target_names, feature_names, DERCR
1) data: 피처들의 데이터 값
2) target: 분류일 때는 레이블 값, 회귀일 때는 숫자 결괏괎 데이터 셋
3) target_names: 개별 레이블의 이름
4) feature_names: 피처의 이름
5) DESCR: 데이터 셋에 대한 설멸과 각 피처의 설명
<예제>
from sklearn.datasets import load_iris
iris = load_iris()print(type(iris))
print(iris.keys())
print(iris.DESCR)
print(iris.data) 
print(iris.feature_names) 
print(iris.target_names)
print(iris.target)
2. 분류나 클러스터링을 위한 표본 데이터로 생성될 수 있는 데이터 셋
| 용도 | API명 | 설명 |
| 분류 | datasets.make_classifications() | 특히 높은 상관도, 불필요한 속성 등의 노이즈 효과를 위한 데이터를 무작위로 생성 |
| 클러스터링 | datasets.make_blobs() | 군집 지정 개수에 따라 여러 가지 클러스터링을 위한 데이터 셋을 무작위로 생성 |
데이터 분리, 검증 & 파라미터 튜닝 - sklearn.model_selection
1. 학습/테스트 데이터 셋 분리 - train_test_split()
(1) 과적합 방지를 위해서 train_test_split()를 통해 원본 데이터 셋에서 학습 및 테스트 데이터 셋으로 분리
(2) 고정된 학습 데이터와 테스트 데이터로 평가하면 테스트 데이터에만 최적의 성능을 발휘할 수 있도록 편향되게 모델을 유도할 수 도 있다. => 과적합에 대한 문제점 여전히 남는다.
(3) train_test_split()는 (학습용 피처, 테스트용 피처, 학습용 레이블, 테스트용 레이블)의 튜플형태로 값을 반환
(4) 파라미터
1) 피처 데이터 셋
2) 레이블 데이터 셋
3) test_size
4) shffle: 데이터를 분리하기 전에 섞을지에 대한 여부. 디폴트 = True
5) random_state: 호출할 때마다 동일한 학습/테스트용 데이터 셋을 생성하기 위해 주어지는 난수 값
<예제1>
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size = 0.3, \
random_state = 112)<예제2>
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
iris_df = pd.DataFrame(iris.data, columns=iris.feature_names)
iris_df['target'] = iris.target
iris_df['target_names'] = iris.target_names[iris.target]
train_set, test_set = train_test_split(iris_df, test_size=0.3, random_state=1004)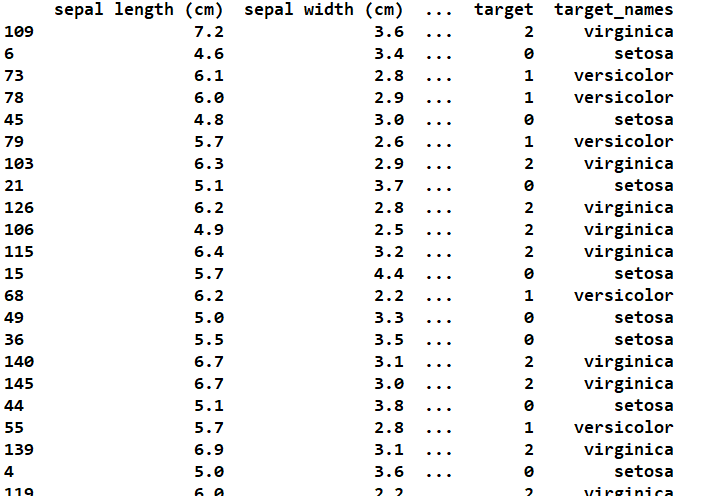
2. 교차검증
(1) 학습/테스트 데이터 분리로도 여전히 남는 문제점 보완 가능
(2) 별도의 여러 세트로 구성된 학습 데이터 세트와 검증 데이터 세트에서 학습과 평가를 수행하고, 각 세트에서 수행한 결과에 따라 하이퍼 파라미터를 튜닝으로 모델 최적화
(3) 대부분의 ML 모델의 성능 평가는 원본 데이터를 학습/검증/테스트용 데이터셋으로 나누어 테스트 데이터로 최종 평가전에 검증 데이터로 학습된 모델을 교차 검증 기반으로 1차 평가한다.
(4) K-폴드 교차 검증
1) K개의 데이터 폴드 세트를 만들어서 K번만큼 각 폴드 세트에 학습과 검증 평가를 반복적으로 수행하는 방법
2) 원리
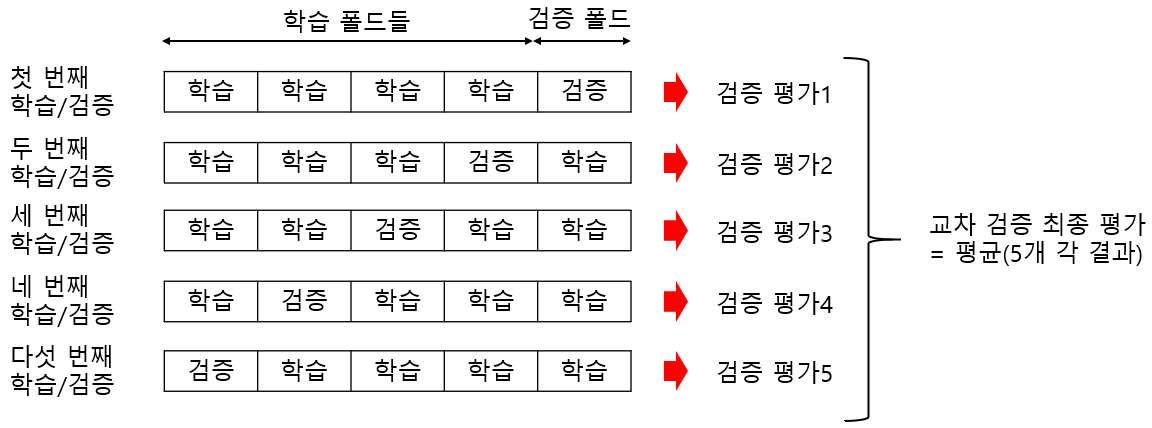
3) KFold()로 데이터 학습, 예측 단계
① KFold(n_splits = 폴드 개수): KFold 객체 생성
② for 루프에서 반복으로 학습 및 테스트 데이터의 인덱스 추출 - KFold의 split(features)을 호출
a. 전체 데이터를 n_splits 수 만큼의 폴드 데이터 셋으로 분리
b. 학습/검증용 데이터로 분할할 수 있는 인덱스 반환 -> 학습/검증용 데이터 추출은 이 인덱스를 기반으로 개발 코드에서 직접 수행
③ 반복적으로 학습과 예측을 수행하고 예측 성능 반환
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import KFold
import numpy as np
from sklearn.datasets import load_iris
iris = load_iris()
features = iris.data
label = iris.target
dtc = DecisionTreeClassifier(random_state = 156)
# 1. 5개의 폴드 세트로 분리하는 KFold 객체와 폴드 세트별 정확도를 담을 리스트 객체 생성
kfold = KFold(n_splits = 5)
cv_accuracy = []
# 2. KFold 객체의 split()를 호출하여 폴드 별 학습/검증용 테스트의 row-index를 array로 반환
n_iter = 0
for train_index, test_index in kfold.split(features):
# 2-1. kfold.split()으로 반환되는 row index를 이용해 학습/검증용 테스트 데이터 추출
x_train, x_test = features[train_index], features[test_index]
y_train, y_test = label[train_index], label[test_index]
# 2-2. 학습 및 예측
dtc.fit(x_train, y_train)
pred = dtc.predict(x_test)
n_iter += 1
# 2-3. 반복 시마다 정확도 측정
accuracy = np.round(accuracy_score(y_test, pred), 4)
train_size = x_train.shape[0]
test_size = x_test.shape[0]
print('\n#{0} 교차 검증 정확도:{1}, 학습 데이터 크기:{2}, 검증 데이터 크기:{3}'.format(n_iter, accuracy,\
train_size, test_size))
print('#{0} 검증 세트 인덱스 test_index:{1}'.format(n_iter, test_index))
cv_accuracy.append(accuracy)
# 3. 각 폴드별 평가 정확도 평균 계산
print('\n## 평균 검증 정확도: ', np.mean(cv_accuracy))
(5) Stratified K 폴드
1) 불균형한 분포도를 가진 레이블 데이터 집합을 위한 K폴드 방식
2) 불균등한 분포를 가진 레이블 데이터 집합: 특정 레이블 값이 특이하게 많거나 매우 적어서 값의 분포가 한쪽으로 치우치는 것 ex) 대출사기 데이터는 대부분이 정상대출이지만 정확한 대출사기를 예측해야한다. 따라서 원본 데이터와 유사한 대출 사기 레이블 값의 분포를 학습/테스트 세트에도 유지해야한다.
3) K 폴드가 레이블 데이터 집합이 원본 데이터 집합의 레이블 분포를 학습/테스트 세트에 제대로 분배하지 못하는 경우의 문제를 해결해준다.
4) 원본 데이터의 레이블 분포를 먼저 고려한 뒤 이 분포와 동일하게 학습/검증 데이터 세트를 분배한다.
5) 일반적으로 분류는 교차에서의 교차검증은 Stratified K 폴드로 분할
6) 회귀에서 레이블이 연속형이므로 결정값 별로 분포를 정하는 것이 의미가 없으므로 Stratified K 폴드를 지원하지 않는다.
7) StratifiedKFold(n_splits)로 데이터 학습, 예측 단계
① StratifiedKFold(n_splits = 폴드 개수): StratifiedKFold 객체 생성
② for 루프에서 반복으로 학습 및 테스트 데이터의 인덱스 추출 - StratifiedKFold의 split(features, label)을 호출
a. 전체 데이터를 n_splits 수 만큼의 폴드 데이터 셋으로 분리
b. 학습/검증용 데이터로 분할할 수 있는 인덱스 반환 -> 학습/검증용 데이터 추출은 이 인덱스를 기반으로 개발 코드에서 직접 수행
③ 반복적으로 학습과 예측을 수행하고 예측 성능 반환
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import StratifiedKFold
import numpy as np
from sklearn.datasets import load_iris
iris = load_iris()
features = iris.data
label = iris.target
dtc = DecisionTreeClassifier(random_state = 156)
# 1. 3개의 stratified K 폴드 설정
skf = StratifiedKFold(n_splits = 3)
cv_accuracy = []
# 2. StratifiedKFold 객체의 split()를 호출하여 폴드 별 학습/검증용 테스트의 row-index를 array로 반환
n_iter = 0
for train_index, test_index in skf.split(features, label):
# split()으로 반환된 인덱스를 이용해 학습/테스트 데이터 추출
x_train, x_test = features[train_index], features[test_index]
y_train, y_test = label[train_index], label[test_index]
# 학습 및 예측
dtc.fit(x_train, y_train)
pred = dtc.predict(x_test)
n_iter += 1
# 반복 시마다 정확도 측정
accuracy = np.round(accuracy_score(y_test, pred), 4)
train_size = x_train.shape[0]
test_size = x_test.shape[0]
print('\n#{0} 교차 검증 정확도:{1}, 학습 데이터 크기:{2}, 검증 데이터 크기:{3}'.format(n_iter, accuracy,\
train_size, test_size))
print('#{0} 검증 세트 인덱스 test_index:{1}'.format(n_iter, test_index))
cv_accuracy.append(accuracy)
# 3. 각 폴드별 평가 정확도 평균 계산
print('\n## 교차 검증별 정확도: ', np.round(cv_accuracy, 4))
print('\n## 평균 검증 정확도: ', np.mean(cv_accuracy))
(6) cross_val_score()
1) KFold나 stratified K 폴드의 학습/예측 3단계를 한꺼번에 수행해주는 API
2) API는 내부적으로 estimator를 학습(fit), 예측(predict), 평가(evaluation)시켜주므로 간단하게 교차 검증 수행 가능
3) cross_val_score(estimator, X, y=None, scoring=None, cv=None)
① estimator: 분류(classifier) 또는 회귀(regressor) 알고리즘
② X: 피처 데이터 세트
③ y: 레이블 데이터 세트
④ scoring: 예측 성능 평가 지표
⑤ cv: 교차 검증 폴드 수
4) cv로 지정된 횟수만큼 scoring 파라미터로 지정된 성능 지표 측정 값들을 배열 형태로 반환
5) estimator가 분류 알고리즘으로 입력되면 Stratified K폴드 방식으로 학습/테스트 데이터 세트 분할
6) estimator가 회귀 알고리즘으로 입려되면 KFold 방식으로 학습/테스트 데이터 세트 분할
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import cross_val_score, cross_validate
import numpy as np
from sklearn.datasets import load_iris
iris = load_iris()
features = iris.data
label = iris.target
dtc = DecisionTreeClassifier(random_state = 156)
# 성능 지표: 정확도(accuracy), 교차 검증 세트 3개
scores = cross_val_score(dtc, features, label, scoring='accuracy', cv = 3)
print('교차 검증별 정확도:', np.round(scores, 4))
print('평균 검증 정확도:', np.round(np.mean(scores), 4))
(7) cross_validate()
1) cross_val_score()와 비슷하지만 평가 지표를 복수 개 반환 가능
2) 학습 데이터에 대한 성능 평가와 수행 시간 함께 반환
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_validate
import numpy as np
from sklearn.datasets import load_iris
iris = load_iris()
features = iris.data
label = iris.target
dtc = DecisionTreeClassifier(random_state = 156)
# 성능 지표 2개, 교차 검증 세트 3개, return_train_score = False는 train의 평가 지표들은 보여주지 않는다.
scores = cross_validate(dtc, features, label, cv = 3, scoring=('accuracy', 'adjusted_rand_score'), \
return_train_score = True)
print (scores.keys())
print('학습 진행 시간:', scores['fit_time'])
print('테스트 수행 시간:', scores['score_time'])
print('교차 검증별 정확도:', np.round(scores['test_accuracy'], 4))
print('평균 검증 정확도:', np.round(np.mean(scores['test_accuracy']), 4))
데이터 전처리 - sklearn.preprocessing
데이터 전처리: 데이터 클렌징 작업, 인코딩 작업, 데이터 스케일링/정규화 작업 등으로 머신러닝 알고리즘을 최적으로 수행될 수 있데 데이터를 사전 처리하는 작업
1. 클렌징 작업
(1) 오류 데이터의 보정
(2)결손 값(NaN, Null) 처리
1) 결손 값이 많지 않다면 제거를 하거나 피처의 평균 값 등으로 대체 가능
2) 결손 값이 많다면 피처자체를 드롭
3) 해당 피처의 중요도가 높고 Null을 단순히 피처의 평균 값으로 대체할 경우 예측 왜곡이 심할 수 있다면 업무 로직 등을 상세히 검토해 더 정밀한 대체 값을 선정해야 한다.
(3) 문자열 처리
1) 머신러닝 알고리즘은 문자열 값을 입력 값으로 허용하지 않으므로 인코딩하여 숫자 형으로 변환해야 한다.
2) 문자열 피처는 일반적으로 카테고리 형 피처와 텍스트 형 피처를 의미
① 카테고리형 피처는 코드 값으로 표현
② 텍스트형 피처는 벡터화하거나 불필요한 피처는 삭제 ex) 주민번호나 단순 문자열 아이디 같은 식별용도의 피처들은 삭제
2. 데이터 인코딩
(1) 레이블 인코딩(Label Encoding)
1) 카테고리 피처를 코드형 숫자 값으로 변환
2) 사이킷런의 LabelEncoder 클래스로 구현
① LabelEncoder() 객체 생성
② fit()과 transform()으로 인코딩 수행
from sklearn.preprocessing import LabelEncoder
items = ['TV', '냉장고', '전자레인지', '컴퓨터', '선풍기', '선풍기', '믹서', '믹서']
# LabelEncoder 객체 생성
encoder = LabelEncoder()
# fit()과 transform()으로 인코딩 수행
encoder.fit(items)
labels = encoder.transform(items)
print('인코딩 변환 값:', labels)
print('인코딩 클래스:', encoder.classes_)
print('디코딩 원본 값:', encoder.inverse_transform(labels))
3) 선형회귀와 같은 ML 알고리즘에서는 변환된 숫자의 크기를 순서나 중요도로 인식해서 예측 성능을 떨어뜨리는 경우가 발생할 수 있다. 예를 들어, 냉장고가 1, 믹서가 2인데 2가 1보다 더 크므로 더 중요하게 인식. 단순 코드로 인식안함
4) 트리계열의 ML 알고리즘은 숫자의 크기를 순서나 중요도로 인식하지 않으므로 레이블 인코딩을 사용해도 된다.
(2) 원-핫 인코딩(One-Hot Encoding)
1) 피처 값의 유형에 따라 새로운 피처를 추가해 고유 값에 해당하는 컬럼에만 1을 표시하고 나머지에는 0으로 표시하는 방식
2) 숫자의 크기를 인식하는 레이블 인코딩의 문제점을 해결하기 위한 방식
import numpy as np
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
items = np.array(['TV', '냉장고', '전자레인지', '컴퓨터', '선풍기', '선풍기', '믹서', '믹서'])
# 2차원 데이터로 변환
labels = items.reshape(-1, 1)
print('labels')
print(labels)
print()
# 원-핫 인코딩
oh_encoder = OneHotEncoder()
oh_encoder.fit(labels)
oh_labels = oh_encoder.transform(labels)
print('oh_labels')
print(oh_labels)
print()
print('원-핫 인코딩 데이터')
print(oh_labels.toarray())
print()
print('원-핫 인코딩 데이터 차원')
print(oh_labels.shape)

from sklearn.preprocessing import LabelEncoder, OneHotEncoder
items = ['TV', '냉장고', '전자레인지', '컴퓨터', '선풍기', '선풍기', '믹서', '믹서']
# LabelEncoder 객체 생성
encoder = LabelEncoder()
# fit()과 transform()으로 인코딩 수행
encoder.fit(items)
labels = encoder.transform(items)
# 2차원 데이터로 변환
labels = labels.reshape(-1, 1)
print('labels')
print(labels)
print()
# 원-핫 인코딩
oh_encoder = OneHotEncoder()
oh_encoder.fit(labels)
oh_labels = oh_encoder.transform(labels)
print('oh_labels')
print(oh_labels)
print()
print('원-핫 인코딩 데이터')
print(oh_labels.toarray())
print()
print('원-핫 인코딩 데이터 차원')
print(oh_labels.shape)
※ pandas에서 원-핫 인코딩하는 API: get_dummies()
import pandas as pd
df = pd.DataFrame({'items':['TV', '냉장고', '전자레인지', '컴퓨터', '선풍기', '선풍기', '믹서', '믹서']})
oh_en = pd.get_dummies(df)
print(oh_en)
3. 피처 스케일링과 정규화
(1) 피처 스케일링(feature scaling): 서로 다른 변수의 값 범위를 일전한 수준으로 맞추는 작업
(2) 피처 스케일링에는 대표적으로 표준화와 정규화가 있다.
(3) 표준화(Standardization): 데이터의 피처 각각이 평균이 0이고 분산이 1인 가우시안 정규 분포를 가진 값으로 변환하는 것 - StandardScaler()
1) 서포트 벡터 머신(SVM), 선형회귀, 로지스틱 회귀는 데이터가 가우시안 정규분포를 가진다라는 가정하에 구현되었기 때문에 사전에 표준화 적용을 하는 것이 예측 성능 향상에 중요한 요소가 될 수 있다.
2) 단계
① StandardScaler() 객체 생성
② fit()과 transform() 또는 fit_transform() 호출해서 변환
a. fit()은 데이터 변환을 위한 기준 정보 설정
b. transform()은 fit()으로 설정된 정보를 이용해서 데이터를 변환
(4) 정규화(Normalization): 서로 다른 피처의 크기를 통일하기 위해 크기를 변환해주는 것 - MinMaxScaler()
1) 데이터 값을 0과 1 사이의 범위 값으로 변환(음수가 포함되어있는 데이터라면 -1과 1사이의 값으로 변환)
2) 데이터의 분포가 가우시안 정규분포가 아닐 경우 적용 가능
3) 단계
① MinMaxScaler() 객체 생성
② fit()과 transform() 또는 fit_transform() 호출해서 변환
a. fit()은 데이터 변환을 위한 기준 정보 설정
b. transform()은 fit()으로 설정된 정보를 이용해서 데이터를 변환
(5) 벡터 정규화 또는 정규화: 사이킷런의 Normalizer 모듈. 일반적인 정규화와 달리 개별 벡터를 모든 피처 백터의 크기를 나눠 계산하는 선형대수의 정규화 개념이 적용
(6) 학습데이터와 테스트 데이터의 fit(), transform(), fit_transform()을 이용해 스케일링 변환 시 유의할 점
1) 가능하다면 전체 데이터의 스케일링 변환을 적용한 뒤 학습과 테스트 데이터로 분리
2) 1)번이 여의치 않다면 학습 데이터에 fit()된 Scaler 객체를 이용해 테스트 데이터는 fit()을 또 하지말고 transform()만 적용
from sklearn.preprocessing import MinMaxScaler, StandardScaler
mn_scaler = MinMaxScaler()
mn_scaler.fit(train)
train = mn_scaler.transform(train)
test = mn_scaler.transform(test)'머신러닝 정리' 카테고리의 다른 글
| 1. 머신러닝 개요 (0) | 2021.06.02 |
|---|




